Sendgrid pricing plans explained
10pm, 5th May 2013 - Web, DeveloperRunning your own mail delivery servers is difficult. It's easy to get it wrong and end up on every blacklist available. Even if you aren't on blacklists, there are still plenty of ways to end up sending your emails to the bit bucket instead of your customers. Sendgrid's promise is to run your mail servers for you and do it right. But which pricing plan should you choose?
Sendgrid have pricing plans available to suit everyone from fresh startups with more co-founders than customers to multinationals with more customers than Australia has sheep.
While these pricing plans seem quite simple, getting the best value for money can be a bit tricky. When exactly is it worth upgrading from Silver to Gold? The Silver plan comes with 100,000 credits but if you thought the right time to upgrade was as soon as you are sending more than 100,000 emails per month you would be wrong. The Silver plan is still cheaper than the Gold plan when you are sending 200,000 emails per month.
When should you upgrade from Gold to Platinum? Not at 300,000 and probably not even 700,000. There is so little difference between these two plans above 700,000 emails per month that even when you are sending a million emails per month you are only paying $15 extra on the Gold plan but if you have a quiet month and dip below 600,000 you are $50 worse off on the Platinum plan. It's safer on the Gold plan if your email volume is at all variable.
To help SocialGO figure this out, I plotted all the pricing plans on a pair of charts which I have reproduced below:
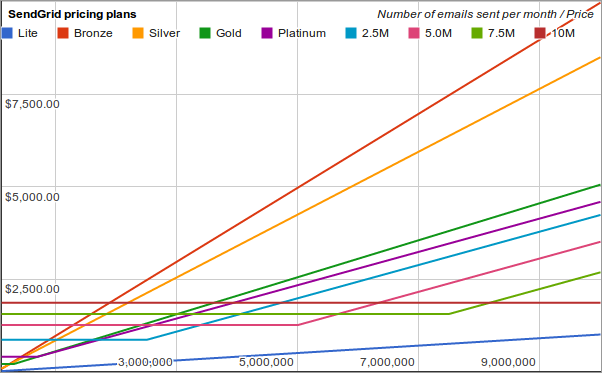
To use the charts, simply find the number of emails you expect to send each month on the X-axis and move upwards until you find the lowest price line. That's the cheapest plan for your chosen number of emails.
For some companies it's difficult to predict how many emails you will send each month. If you know that your sending volume could swing up or down by 30% each month, find the upper and lower volumes of emails you could send and choose the line that has the lowest average in between those two points.
It gets a bit small and difficult to read down at the lower end of the price plans so here's a detailed version for those sending fewer than a million emails per month:
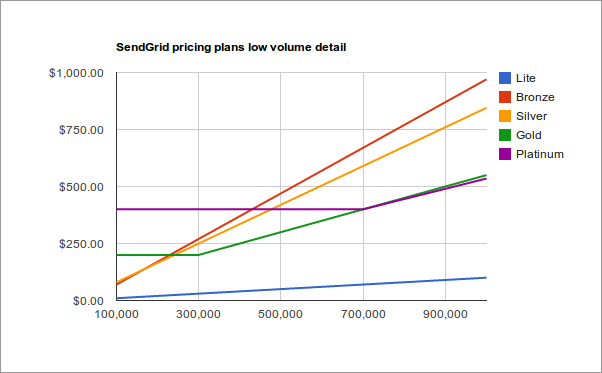
Both of these charts start at 100,000 emails per month. Below that the plans differ in both features and price so the chart would not be giving you the full picture. The Lite plan shown as a blue line at the bottom also differs quite significantly in its features. There's a reason it is so much cheaper. It compares quite closely to Amazon's SES offering. Amazon only have one plan but they charge you separately for bandwidth and they don't offer all the same features as Sendgrid.
Sendgrid also have higher volume plans. On their pricing plans page it simply says to contact them if you plan on sending more than 1.7 million emails per month. When I did contact their sales department, I got a response with the plans labeled 2.5M, 5.0M, 7.5M and 10M on the first chart.
No one wants to pay too much for their email service. With these charts, you can optimise your Sendgrid plan so that you don't waste any money.
The Middle Name Guesser
5am, 27th January 2009 - Geek, Interesting, DeveloperI have recently made some improvements to the Middle Name Guesser (one of which was to make it actually work again) and I'd like to take this opportunity to invite you to have it guess your middle name... or your friend's middle name, or your favourite celebrity's middle name.
I have also added a couple of statistics graphs and you can clearly see exactly when I fixed that pesky little bug that only showed up when it actually guessed your middle name correctly. (It was a typo I introduced the last time I edited the file - a strong argument for automated testing if ever I heard one.) At that point it was getting about 1 in 20 guesses correct. Since then it has been steadily improving up to a peak of getting 1 in 4 guesses correct. 1 in 4 guesses correct is better than I ever hoped it would achieve. I was originally thinking that 1 in 10 would be a good result. Now I'm wondering if it will get to 1 in 2...
I expect to see the ratio of correct to incorrect guesses remain relatively unstable until the number of new, unique middle names, first names and last names (the red, blue and purple line) starts flattening out. After that the ratio should only improve as the relationships between the known first and last names and middle names are strengthened.
The air powered car
9am, 15th January 2008 - Geek, Interesting, Hardware, Science There's an air powered car that has been causing some hype recently (which, I suppose, is considered "fuel" for this new car. Heh.) and, while it's not all that new, some people are cautiously (and not so cautiously) predicting that "2008 is the year of the air powered car". As a born skeptic, I felt the urge to play devil's advocate.
There's an air powered car that has been causing some hype recently (which, I suppose, is considered "fuel" for this new car. Heh.) and, while it's not all that new, some people are cautiously (and not so cautiously) predicting that "2008 is the year of the air powered car". As a born skeptic, I felt the urge to play devil's advocate.
My first thought was that the compressed air has to come from somewhere and that the process of compressing the air would require energy from more traditional sources. This technology isn't a new way of generating or extracting energy. Much like the talk of Hydrogen-powered cars, this is a new method of storing energy in cars that has been generated somewhere else. Most of these sorts of schemes don't help reduce pollution, they just offset it somewhere else. While this is good for people who live in cities, it's not any better for the planet as a whole.
 But there may be more to this plan than just offsetting the pollution. A compressed-air powered car has a few advantages over a Hydrogen powered car: Hydrogen has to be converted from it's pure state into a form with a lower energy content or higher entropy. This is usually achieved by combining it with Oxygen, which is readily found in the atmosphere. The process of combustion usually takes place inside a modified conventional engine or in a Hydrogen based fuel cell, however, both of these methods generate lots of wasted energy. The power extracted from the Hydrogen comes from the expansion of the gases as they combine. The sound and heat energy that is produced at the same time is dissipated into the environment and is wasted.
But there may be more to this plan than just offsetting the pollution. A compressed-air powered car has a few advantages over a Hydrogen powered car: Hydrogen has to be converted from it's pure state into a form with a lower energy content or higher entropy. This is usually achieved by combining it with Oxygen, which is readily found in the atmosphere. The process of combustion usually takes place inside a modified conventional engine or in a Hydrogen based fuel cell, however, both of these methods generate lots of wasted energy. The power extracted from the Hydrogen comes from the expansion of the gases as they combine. The sound and heat energy that is produced at the same time is dissipated into the environment and is wasted.
A compressed-air powered car, on the other hand, can extract the same gaseous expansion based energy as combustion based cars without the loss of the heat and sound-based energy. There has been some discussion (although the results I found were inconclusive) about whether the process of compressing the air was inefficient enough to offset the gains made with the more efficient power stations and in-car decompression process. The end result of reducing waste energy is that not only would the car cause less noise pollution, but the energy used to actually drive the car could be a greater percentage of the total energy available. Less waste is a good thing.
 There are, however, a few elements of the article that caused me some concern. The talk of the compressed air driving the pistons which in turn compress the air makes little sense. This is akin to using an electric motor to drive a generator which powers the electric motor. If it worked, it would violate the law of conservation of energy. I suspect (hope) that an over-enthusiastic reporter snuck this into the article rather than quoting directly from a scientist.
There are, however, a few elements of the article that caused me some concern. The talk of the compressed air driving the pistons which in turn compress the air makes little sense. This is akin to using an electric motor to drive a generator which powers the electric motor. If it worked, it would violate the law of conservation of energy. I suspect (hope) that an over-enthusiastic reporter snuck this into the article rather than quoting directly from a scientist.
The article also makes no mention of the range of the car apart from stating that there is a long-range version that would be fitted with a conventional engine. This suggests to me that this new car would suffer from the same drawbacks that electric cars suffer from: a range so small that the car is limited to the inner-city commute from home to work. After a quick Google and a visit to WikiPedia, it appears that other sites claim the range would be somewhere between 100Km - 200Km. That's great for those who only need that but I won't be swapping the long-range fuel tank in my Pajero for one of these until it comes closer to the same range. Earlier articles regarding the same technology suggest even lower ranges so with the technology getting better and better, hopefully the air car will achieve that goal eventually.
 Filling me with confidence again, the rest of the article shows that Negre (The motivation behind the idea) truly understands the problem of wasted energy. Firstly, the direct quote: "The lighter the vehicle, the less it consumes and the less its pollutes and the cheaper it is; it's simple," is very similar to one of the major principles behind low-energy building design. So often, when you design something inefficiently, you find that you need to waste more energy to fix problems with the design. Cars have added weight to deal with the wasted sound and heat energy which, in turn, requires more energy to carry around. Fridges emit all their heat at the back, which often gets trapped and heats the inside of the fridge back up. Fridges have to use extra energy just to remain below room temperature because the air around the fridge is above room temperature. The less wasted energy a car has, the less weight it needs to carry around to deal with the side-effects of the wasted energy. The less weight it has to carry around, the more you can do with the energy you have. In fact, the expansion of a compressed gas will actually draw in heat - the same way a fridge works - meaning the air can then be used for cooling the interior of the car. An air-conditioner and a radiator are two fewer pieces of machinery this car has to carry around thanks to it's more efficient design.
Filling me with confidence again, the rest of the article shows that Negre (The motivation behind the idea) truly understands the problem of wasted energy. Firstly, the direct quote: "The lighter the vehicle, the less it consumes and the less its pollutes and the cheaper it is; it's simple," is very similar to one of the major principles behind low-energy building design. So often, when you design something inefficiently, you find that you need to waste more energy to fix problems with the design. Cars have added weight to deal with the wasted sound and heat energy which, in turn, requires more energy to carry around. Fridges emit all their heat at the back, which often gets trapped and heats the inside of the fridge back up. Fridges have to use extra energy just to remain below room temperature because the air around the fridge is above room temperature. The less wasted energy a car has, the less weight it needs to carry around to deal with the side-effects of the wasted energy. The less weight it has to carry around, the more you can do with the energy you have. In fact, the expansion of a compressed gas will actually draw in heat - the same way a fridge works - meaning the air can then be used for cooling the interior of the car. An air-conditioner and a radiator are two fewer pieces of machinery this car has to carry around thanks to it's more efficient design.
Negre also has plans to use small factories in the same regions where the car is to be sold. This will probably cost slightly more - large scale factories have the advantage of being cheap on a per-car basis - but it will cost the environment less. He stated that the parts would not be shipped to the factory to be assembled but would rather be sourced locally - saving again on the environmental costs of shipping.
It's possible, with the advances in technology we have made, that the whole process may just even turn out cheaper in dollars than shipping the cars half-way around the world. Wasted energy and wasted effort are wasted dollars. If Negre understands this, and I think he does, then this venture should turn a profit for both his bank balance and the environment.
MoneySavingExpert under DDoS attack
11pm, 30th October 2007 - Geek, News, Web, Security, Sysadmin, Hardware Last weekend, MoneySavingExpert (my old employer) was the subject of what appears to be a fairly hefty DDoS attack. It has been reported on several blogs and shortly afterwards on Digg.
Last weekend, MoneySavingExpert (my old employer) was the subject of what appears to be a fairly hefty DDoS attack. It has been reported on several blogs and shortly afterwards on Digg.
There has been much speculation about why it's happening just now and who could be behind it but, as always, without any data to analyse there's no way of making any guess more accurate than a wild stab in the dark. There has also been much wailing and gnashing of teeth about the powerlessness one feels when being attacked by half the internet. Not that the tech team over at Money Saving Towers were wailing or gnashing their teeth, they just got in and fixed the problem. By Sunday afternoon there was a static holding page up which I could actually request and receive in a browser and by Monday morning the site appeared to be back up and running as usual although I think the forums were still down at that time.
There are some things that can be done when you are the victim of a DoS attack. If MoneySavingExpert can survive it, then so can you.
How you deal with a DoS depends greatly on how it's happening. If you don't already know why your site is down, start trying to find the reason. Log files and aggregated statistics are always the first two places I look.
At my current place of employment, we have a series of graphs generated using Orca and RRDTool for each of our servers. These graphs show us everything from CPU load to disk space used to the number of open TCP connections to the machine's uptime. If a particular server is causing the problem then I can load all of its graphs in a single window and scroll down the list looking for anything unusual. If the problem is with a particular website then I can load up just the servers that website affects. If I don't know which part of our system is the cause of the downtime, then I can load them all up.
Unusual patterns in log files can also be an indicator that something is wrong. If I notice that one IP address has requested more web pages than the next ten combined then I start to suspect that something is wrong at that IP address. If I notice that today's log file is twenty times the size of yesterday's log file, then I'm going to want to have a look inside both of them. At this stage, all I'm doing is gathering information because I don't even know if it's a deliberate DoS or just some other sort of site outage. Either way, the logfiles often hold the answer.
There are many different ways a DoS can be caused. Simply flooding a webserver with ten times the normal number of requests it has to deal with is a crude but effective method. This method will often cause your upstream bandwidth provider to start dropping packets because it can't keep up the pace. Even if your webserver could serve all the requests, some of them won't make it all the way there. Other types of DoS exist, however, and it's worth mentioning some of them here.
There are plenty of vulnerabilities in the off-by-one-buffer-overflow category that will cause a program to crash. These are inevitably classed as denial of service vulnerabilities because that's usually all that can be exploited with them. The important thing to note is that you don't need a large botnet or even a small one to cause a DoS to someone using this method. All an attacker needs is a single computer with the ability to anonymise it's payload through something like ToR or a list of proxy servers. Every crash (i.e every request) is going to cause several minutes of downtime.
Another class of DoS attack is caused by requesting a page that causes a lot of resource usage, such as requesting '%' from a badly written search function. If the page is vulnerable, this example will cause the result set of the search to include every row in the database. This will chew up large amounts of CPU and RAM even if it only actually displays the top ten results.
A DoS attacker could also request pages that cause lots of logging to occur, hence filling up the victim's file system. I have actually caused this to happen completely by accident on one guy's website. Apparently, in the space of about half an hour I caused 60GB of log files to be generated on their webserver. Luckily, they knew what I was doing and had my phone number so they could ask me to stop.
These sorts of attacks - the ones that cause resource starvation on your webserver - can be caught with an IDS such as Snort, any decent firewall or a dedicated appliance. Once you can identify the packets that are part of the DoS it is simply a matter of knowing how your firewall/IDS is configured and configuring it to drop those packets.
The other sort of DoS attack - the sort that attacks the services that support your site rather than the site itself - cannot be stopped by you. They will require the people who run the service that failed to do whatever they need to do to survive the attack. In the case of MoneySavingExpert, it appears that they have requested the services of ProLexic, a company that specialises in mitigating the effects of bandwidth-based DDoS attacks. Essentially, ProLexic point all of the victim's traffic at their own servers, filter out the bad requests and pass the remaining requests on to the real webservers. It's a simple but effective tactic that works against the crude but effective attack.
Little Bobby Tables
5pm, 14th October 2007 - Geek, Humour, Web, Security, Developer Ahhh xkcd, you've done it again.
Ahhh xkcd, you've done it again.
There's not enough security humour in this world.

I want to name my cat Tiddles"><script>alert('Foo!');</script> now, just so that I can put that in as the answer to my secret question on Facebook.
I just remembered that xkcd always put a title tag on every image that contains another little joke. I've replicated the title-tag joke for this comic here as well. If you're using Firefox, you can hover over the image to read it.
So many servers, all hacked.
11am, 13th October 2007 - Geek, Interesting, Web, Security, DeveloperYesterday, while trying to track down a problem with one of our forums, I was looking through the validation log and spotted something rather unusual.
The validation log stores all the parameters passed to the forums that failed validation so that we can verify that no legitimate users are being denied access. Parameters include things like which post you are looking at, which thread it's in, which board the thread's in and which page of the thread you are on. Normally, the post number, thread number and page number are all actually numbers but occasionally, somebody thinks it might be a good idea to put something else, like a URL, into the post number parameter.
The result was astounding.
I sat there for minutes, watching the URLs of compromised servers fly past on my screen. In this case, it was a misguided hacking attempt aimed at a completely different piece of software than the one we are running. We didn't have the vulnerability he was trying to exploit. Had it been aimed at the correct software and succeeded, it would have would have changed the parameter so that instead of including a PHP file from the webserver, it would have included a file from someone else's webserver and run that file just as it does when the file is local. The difference is that the code from the other webserver would have installed a rootkit, a command and control interface, a couple of new users and finally sent a message back to it's owner telling him where we were.
Unfortunately, people who try to seize control of other people's webservers are a paranoid lot. They don't usually just start hacking from their home computer and head straight for the target. They will use Tor or an anonymous proxy to mask their true identities. They'll use webservers that they have already cracked to help crack new webservers. In this case, tracing the hacking attempt back to where it came from only lead us to another compromised server with a web-based command and control page and the file required to hack other servers.
I didn't pursue it any further for several reasons: I'm not paid to hunt down crackers, it would have been illegal for me to use the compromised server to find out where it had been compromised from and it was an unsuccessful attempt to exploit a vulnerability we didn't even have. Out of interest, I did quickly grep through the entire set of validation logs just to see how many of these attempts there were and from how many already-compromised webservers. The result was astounding. I sat there for minutes, watching the URLs of compromised servers fly past on my screen.
I wasn't all that surprised to see lots of hacking attempts. Just put a machine on the internet running Snort for a day and you'll understand why. What did surprise me was the sheer number of already compromised servers sitting out there. Do people not have intrusion detection systems ? Do they not check their log files ? Has somebody like me not already noticed that their server has been hacked and emailed to let them know ? (For the record, I did email the admin of the first server but once I found the hundreds or thousands in the log files I decided that it was a bit much effort for me...)
Does security not matter to these people ?
I suspect that's the answer. Most people are on the net to create something. They aren't interested in learning all about computer security and how to secure their machines. They just want to create their own little corner of the web where they can do as they please.
Security implications of data recovery
4pm, 23rd September 2007 - Geek, Interesting, Security, Developer, Sysadmin, Legal![]() After last week's data recovery antics, I started looking at what is actually stored in Firefox's crash recovery file (sessionstore.js) and it appears to be ripe and juicy for a bit of password sniffing. A quick search though the file and I found one of my passwords hiding in plain sight along with the associated username. Although the file has restrictive permissions (600) anyone with admin/root privileges would be able to read it. Anyone who can login with your privileges would be able to read it. Anyone who has access to your computer, even for only a couple of minutes would be able to read that file.
After last week's data recovery antics, I started looking at what is actually stored in Firefox's crash recovery file (sessionstore.js) and it appears to be ripe and juicy for a bit of password sniffing. A quick search though the file and I found one of my passwords hiding in plain sight along with the associated username. Although the file has restrictive permissions (600) anyone with admin/root privileges would be able to read it. Anyone who can login with your privileges would be able to read it. Anyone who has access to your computer, even for only a couple of minutes would be able to read that file.
Sure, "root can already do anything" you say, but this allows whoever is root to gain extra privileges. Privileges on another system where he isn't already root. This is your gmail password, your MySpace password, your banking password. Maybe, this is the same password you use for all of your accounts on all your social networking websites.
It doesn't seem to matter whether the password is in a "password" field or just a plain text field and it doesn't matter whether the page is encrypted or not. Your password will be stored, with the username it accompanies, in plain text in your home directory.
This isn't just limited to passwords either. What if you logged in under an anonymous name at some forums somewhere so you could blow the whistle on your corrupt boss without fear of sacking ? What if you were emailing the blueprints to you next invention to the patent office ? What if you were uploading photographs you had taken in secret from your hotel across the road from the US embassy to a Russian spy website ? What if something even more unlikely and implausible were to happen that would be devestating to you if it were discovered you were the culprit ?
The lesson to learn is that if your data can be recovered by you after a crash, it can be recovered by pretty much anyone at any time. If you're a developer, remember this and think about not storing passwords or at least storing them encrypted.
How to recover your data after a crash
9pm, 17th September 2007 - Geek, Interesting, Apple, Linux, Sysadmin, HardwareYears ago, back in the days of 33MHz processors and Mac OS 7, my little brother was writing a letter to our Granny when the computer he was using crashed. Crashes were good in those days; you got a little box on your screen with a picture of a bomb in it, a cryptic crash message and a restart button. As I was the resident computer geek, I was immediately called for and asked if anything could be done.
Luckily, at the time I had a voracious appetite for anything that looked like it could teach me how to program and I had read everything remotely technical I could find on the internet. I had, at the time, recently read about how to use Mac OS's built in debugger to save the contents of RAM to a file on the hard disk and I guessed that this could be used to recover my brother's letter. It took me a couple of goes to remember how to do it as I couldn't have the tutorial open while I was in the debugger but I did eventually remember. Shortly afterwards we had a 4MB file sitting on the hard drive that hopefully contained my brother's letter. A quick search through the file and we had recovered nearly all of the letter and put it back in SimpleText where it belonged.
Fast forward to today and things have changed a bit. Operating systems don't have built in debuggers that you can invoke with a keystroke (Well, some do, but not usually by default.) and 4MB of RAM is not considered enough to stir your coffee with, let alone boot a kernel into.
None the less, there are still things that can be done if you don't panic and are willing to think about your problem a bit. In my case, I was busy writing up a new blog post. Quite a rant if I remember correctly. I had poured my anger into the keyboard and was just going through it once more to check for spelling errors before posting it when Firefox disappeared. Gone. No warning, no crash dialog, no error message. Just gone.
Immediately I started Firefox back up again hoping I could recover my rant. I didn't want to have to type it all out again. I was hoping that when it restored my session with all it's tabs it would also restore the contents of the blog post field. Alas, it was not to be.
Since that idea had failed to produce any results, I tried the same trick that worked for my brother all those years ago: Save the contents of RAM to a file on the hard disk and look through it for what I had just been writing. Not being sure of how to do this, I fell back on something I did know how to do: copy the contents of virtual memory. I checked /etc/fstab to find out where my swap partition was and then typed dd if=/dev/hdd5 of=/home/dave/swap_partition on the command line.
This saved the contents of swap to a file. Next, I ran the command strings swap_partition > swap_strings.txt which grabbed anything that looked like an ASCII string out of that file. Basically, any text in virtual memory would now be in the file swap_strings.txt. With trepidation, I grepped through the file for a word I know I had typed several times in the blog post. Nothing. I tried another word, and another. Although I was finding plenty of occurrences of the words, none of them were part of the blog post I had just written.
Since another idea had failed to recover my work, I needed to think again. Where else could this data have been saved ? Logically, the next most likely place was the .mozilla directory in my home directory. This is where Firefox saves all of your user-specific profile settings. Under Windows this would be in C:\Documents and Settings\Username\Application Data and on a Mac it would be in /Users/username/Library/Application Support.
Firefox saves all the tabs and all the windows you currently have open on a frequent basis so that if it crashes or shuts down untidily for any reason, at any time, it can start up again exactly where it was and recover any work you were doing. In my case, Firefox had opened all my tabs and remembered what was in the text fields such as the headline and date fields and I had been hoping that it would remember the textarea which contained the majority of the post. I was to be initially disappointed.
Although Firefox hadn't filled the large textarea in when I had returned to the page, I had a feeling that it may have been saving it's content somewhere on disk even though it hadn't been automatically recovered. Sure enough, I ran the strings command over every file I found in the .mozilla directory and one of them - sessionstore.bak - had my blog post in it. The data appeared to have been URL encoded and was mixed up with every other bit of data about the session that had just crashed but neither of these problems were difficult to work around. A few quick search-and-replace commands later and I had recovered all of my writing.
Maybe this will work for you, maybe it won't. The important thing to remember is that even though your data may look to be gone, there's still probably another copy of it floating around somewhere and if you know a couple of good tricks, you might just be able to recover it.
2007-10-16 - Update: I did a bit more research and found out how to dump the contents of RAM and the contents of any single process.
[dave@dave-desktop:~] # sudo cat /dev/mem | strings > ~/mem
The first command will save any ASCII string in RAM to the file mem in your home directory. To save the entire contents of RAM, just remove the
[dave@dave-desktop:~] # sudo gcore -o ~/coredump pid| strings part of the command. This will save all the RAM, even if there isn't a running process using some part of it.[1]
The second command will save the memory of the process pid where pid is actually the process id of the process whose memory you want to dump.
I also found a great page on someone else's experiences with MacsBug almost exactly mirroring mine.
[1]: I tested this by starting vi and typing in "thisisanabsolutelyuniqueteststring", killing the vi process without saving the file and running the command above immediately with a small modification. Instead of piping the output to a file, I piped it to grep thisisanabsolutelyuniquetest. The grep command found itself, as it always does, but it also found the original string, identified by the rest of the unique string that I didn't include in the grep command.
You have to be careful when search through running memory. I now remember having this problem with the Mac all those years ago. Whenever I searched for parts of my brother's letter, I would just end up finding the part of memory that contained the search string.
Burning water not so hot after all
8am, 16th September 2007 - Geek, Rant, NewsSome random Cancer researcher discovers a way to make salty water "burn" by firing radio waves at it. He shows his mates from the Chemistry department and they all get quoted by a reporter as saying that "we want to know whether the energy released will be enough to power a car". The article is copied around everywhere (I have no idea which one was the original.) The world goes crazy.
Think about it for a minute. This is just another perpetual motion machine disguised as a chance discovery by scientists in an unrelated field. People think they've found a way to violate the laws of thermodynamics all the time. Some of them labour under the delusion for quite some time, others realise their mistake but see the potential for a scam and others quietly go back to their research and hope no one noticed their mistake.
If you thought you had just discovered a new, totally clean, excessively abundant energy source, why would you invite a chemist to see it ? Why weren't any physicists invited to see this amazing burning water ? Where are the venture capitalists ? Where is the patent office ?
If any of those people were to become involved in this, they would ask the obvious question: where does the energy come from ? Water has very little energy stored in a way that can be released. It has quite a lot of entropy. Firing radio waves at water causes the hydrogen-oxygen bonds to weaken but requires energy. If you were to measure it, my money would be on the amount of energy being put in to the system in the form of radio waves being slightly greater than the amount of energy extracted from the system in the form of heat. There would also be some unmeasured heat loss and other energy loss in the form of sound and light.
There are two further possibilities. One is that these guys have discovered a new, lower energy, higher entropy form of water that up until now had never been discovered. Maybe there's an extra neutron in there now and they've discovered a cheap way of making Deuterium (heavy water). Maybe there's something weird going on with positrons. Maybe they've successfully achieved cold fusion. Although at 3000 degrees it wouldn't be considered cold any more.
Maybe there's a reason why physics should be left to the physicists. The answers are not in yet but my money is most definitely on this being recorded as a fascinating curiosity, but not a new fuel source.
P.S. To the guy who said that water is the most abundant resource on earth, if I remember my High School Physics correctly, the most abundant compound on Earth by weight is Silicon Tetra-Oxide. This means that although around 29% of the Earth is Oxygen, a fairly large proportion of that is not water. In fact, I just looked it up and apparently around 0.02% of the Earth by weight is water.[1]
Swedish security researcher exposes plaintext passwords found while sniffing Tor
10pm, 12th September 2007 - Geek, Rant, News, Web, Security, Legal![]() As reported on Ars Technica, The Register, Heise Security and Slashdot, the Swedish security researcher Dan Egerstad of DEranged Security has thrust into the limelight a security issue that has been plaguing concerned security technicians for years. Unfortunately, many of the news stories either miss the point entirely or misrepresent Tor as being something it is not and the security vulnerability as being something it, too, is not.
As reported on Ars Technica, The Register, Heise Security and Slashdot, the Swedish security researcher Dan Egerstad of DEranged Security has thrust into the limelight a security issue that has been plaguing concerned security technicians for years. Unfortunately, many of the news stories either miss the point entirely or misrepresent Tor as being something it is not and the security vulnerability as being something it, too, is not.
Tor (The Onion Router) aids anonymity. Anonymity is closely related to privacy. Privacy and security often go hand in hand. Therefore, Tor is a secure network.
Wrong ! Three of the above statements are correct but the conclusion drawn from those is not. Tor is not a magic silver bullet for security and privacy. You can't just hook up to the Tor network and expect that everything you do is now secure.
Now that I have that off my chest, let's look at the security research. Research that, completely coincidentally, a friend of mine and I had been discussing last week in our own attempt to do a very similar thing: Find an appropriate point on a network, set up a packet sniffer and publish every username/password combination we find in an effort to push the encrypted logins only agenda. We're in favour of SSH over Telnet or rlogin, scp over rcp, SFTP over FTP and HTTPS over HTTP.
It's always interesting looking at what people actually choose as passwords. Some of them look to be a good mix of uppercase letters, lowercase letters and numbers, some are just lowercase and numbers, some are just lowercase and some are just numbers. I saw one that was 13 random characters long and another that was literally '1234'. I also saw 'temp' and 'Password' as passwords. I did see a few passwords that had symbols but none with any special characters. (Considering that most of these embassies speak languages other than English, this seems strange...) Even without the aid of packet sniffers, some of these passwords seem trivially easy to brute force.
Some people didn't quite understand what had happened. I'm not mentioning any names but don't fret; Dan did. Dan's site was taken down as requested. There's a well known saying about horses and stable doors that seems to apply here. Worse still, Dan's site had (and still has) instructions on what the actual vulnerability is and why it's a problem. Something that most of the news stories about his research failed to pick up on.
Now, on to the debacle of Chinese whispers around any news site catering to pseudo security that ensued. Each one quoting the last one until the message was completely lost. I suspect that The Register were deliberately sensationalising their headline: "Tor at heart of embassy passwords leak" just to get a few extra readers. Many of the news stories focussed on the fact that it was a Tor exit node that the sniffer was running on when in fact this was merely incidental to the real story. Let me state this very clearly: This could have been ANY machine on the route between the client and the server. Tor made it relatively easy for Dan to get on that route but it's certainly possible to achieve without Tor. The vulnerability is that the usernames and passwords are sent in plain text across an untrusted network (and what network of any moderate size can be trusted ?)
There have been some moderate and intelligent responses to all of this. If you filter your Slashdot discussion just the right way, some serious insight (rather than incite) can be gained into issues associated with the one raised. One user points out that Tor should not be used for tasks that can identify you. Another responds that sometimes you want to hide not who you are but where you are. Yet another user suggests that employees would be fired from government positions for using Tor.
One thing missing, however, is a sense of concern about the implications of this. Everybody seems to be treating it as a warning: Look what could happen if you don't encrypt your network traffic. Bad people could get hold of your passwords ! But what if the people logging in to these email accounts are not the employees we think they are ? Why would an employee need to log in to their own, personal email via Tor ? Why would a terrorist need to log in to an embassy employee's email account using Tor ? The second question appears to be somewhat easier to answer and somewhat harder to digest.
My thought is that Dan Egerstad has missed the real significance of the Tor network, possibly because he was already focussed on Tor in his research and hence didn't see it as an unusual element. The real significance is that these accounts may have been compromised some time ago and the original attackers are regularly reading all of these email accounts, simply using Tor as a method to remain anonymous. They probably have comparable hacking skills as the security researcher who exposed the problem and have enough concern about their own anonymity to take steps to ensure they retain it. The best our officials can come up with is a request to remove Dan's website from the internet. Now there's a worrying thought.
The smoking ban
11am, 27th August 2007 - Rant, News, LegalSince the smoking ban came into effect on the first of July, I have inhaled more second-hand cigarette smoke than in the entire previous year. The ban forces people who used smoke indoors to now smoke out on the street... where I am.
There's a daily gauntlet-run past the Royal Free hospital where patients, visitors and staff alike now all smoke on the street out the front of the hospital. My eyes are watering by the time I get halfway past. There's another one just before I reach my work where all the builders from the worksite next to the building I work in congregate along a pathway barely a metre wide and fill their lungs and my atmosphere with cancerous gunk.
Ironically, I used avoid pubs a little because the smell of smoke would permeate through my clothing and hair and get worse over time. Now, pubs are a safe-house where anybody who would pollute my air must now leave and do it outside. Of course, when I want to leave, I still have to walk through the crowd of people standing just outside the door, smoking as fast as they can so they can get back inside to sit with their mates again.
Still, it's a step forward. Not because it reduces the amount of passive smoking I am forced to endure but because it enables the next step: a total ban on cigarette smoking in all public places.
Eating and watering and generally relaxing
7pm, 31st July 2007 - HumourI found this waiting in for me Trillian when I got back from lunch the other day:
[13:55] the magdaddy: hello little one! did you make lovely logins for jane doe and john doe? do they have to come up to receive their user/pw or can i take them down for them?
[13:55] *** Auto-response sent to the magdaddy: I'm busy. No, really. I am.
[13:55] the magdaddy: no, this is the one time in the day when you are not busy - you are eating and watering and generally relaxing.
[13:55] the magdaddy: you cannot fool me.
Yes indeed, you cannot fool the magdaddy.
Apocalypse tomorrow
4pm, 29th July 2007 - Geek, Interesting, Hardware, Travel I've always been interested in making my own alternative energy. Not so much for it's potential in saving the environment (although that's important too.) but more for the independence it gives me.
I've always been interested in making my own alternative energy. Not so much for it's potential in saving the environment (although that's important too.) but more for the independence it gives me.
I am uncomfortable relying on other people and in our modern society I find myself unable to avoid relying on other people. I live in a house built by other people, I buy food that was grown by other people, I am supplied with water, electricity and gas by other people, I drive a car built by other people and I am typing this on a computer built and programmed by other people. That's part of how modern society works; because I am able to pay money to have somebody else do all these things for me I can specialise on a small number of things I can do and all the people can specialise in what they do. In short, as a whole we are more efficient because we all cooperate.
The problem I have is that if it all went away tomorrow, I wouldn't know what to do. I know how to do some of these things - not as well as the specialists - but I could do them well enough to survive. I have grown my own vegetables, found and collected my own drinking water, built myself a shelter (I can't quite go so far as to call it a house but given time I could get that far) and even generated my own electricity but I don't think that I can do any of them well enough to be comfortable. My house would have leaks and drafts, my vegetables would be small, weedy and only grow in certain times of year, if I could build some transport it wouldn't go much faster than walking pace, the electricity I generated would barely be enough to run a couple of lamps, let alone a computer.
The key to being comfortable is in preparing now. If I learn the skills then I can make my own way forwards. If I make my self sufficient transport device now utilising someone else's help then I'll have it tomorrow, whatever happens around me. The apocalypse is not coming but the same preparations you would make for it can help even without an apocalypse. If you don't have to buy petrol for your car, you can save the money you earn in your job for something else. It doesn't matter why you don't have to buy petrol; you could grow biodiesel, generate hydrogen via solar, hydro, wind or some other power at home and power you car on that or simply convert your car to be solar or wind powered itself. Imagine riding to work each morning on one of these or one of these !
Of course, there are some problems with these modes of transport. The land kite isn't going to work in a city or in large numbers. The kites would just get tangled up in everything. The land yacht has a better chance in the cities but car drivers are still going to be frustrated with these devices on slow wind days. Solar cars have a similar problem; they aren't very good at stopping and accelerating the way you are required to in a city. They're also not very good when a skyscraper blocks the sun. Cars that charge up overnight and run off batteries tend to have a very short range.
The solution to all these problems is cooperation. Just as societies progress by having their members work on their strengths and support each other's deficiencies, a car can progress by having more than one power source available to it. If your car has solar panels, pedals, a battery, a sail and possibly a turbine, it can use the sail when it's windy, use the sun when it's sunny, use the turbine when it's traveling directly into the wind, use the pedals when everything else fails and use all of them to charge the battery when it's stopped at traffic lights or parked. The result of this would be a car that's completely self-sufficient, works all the time, produces zero emissions and doesn't cost a penny to run.
In search of an English summer
9pm, 2nd July 2007 - Rant, News, Humour, TravelA year ago I wrote about the English summer. At that time I was skeptical about my workmate's assertion that this was uncommonly good weather for an English summer. Surely the odd day here and there that made it all the way to 30° couldn't be considered good. But this year has put me straight. Nary a day above 25° and it's been raining pretty much solidly for the last three weeks. On Tuesday, it hailed ! Jane had a snowball fight at her work by scooping up the hail, smooshing it all together and throwing it at her boss !
I take it all back ! Last summer was great ! I didn't mean to offend your summery goodness... now can I please have a little sunshine again before I turn completely white ?
iPhone and Security: Spreading the FUD.
12pm, 30th June 2007 - Geek, Rant, News, Interesting, Apple, Security, Hardware Straight from news.com.com: "Gartner says that iPhone could punch a hole through corporate security." Apparently it "doesn't contain the necessary functionality to comply with basic corporate security."
Straight from news.com.com: "Gartner says that iPhone could punch a hole through corporate security." Apparently it "doesn't contain the necessary functionality to comply with basic corporate security."
What the... ?
Strangely enough, the page that text links to doesn't actually point out any lacking functionality in the iPhone. In fact, it completely ignores the text that links to it, mostly because while the interviewer is lacking a clue, the interviewee clearly has one. Neel Mehta, Team leader for Internet Security Systems at IBM says that the iPhone is more complex than any smart phone to date and hence has a greater potential for security flaws. He also points out that the development model for third party developers means that everything non-Apple is going to run within the sandbox environment of Safari. He also points out that the iPhone is going to be regularly connected to computers and the internet and that updates from Apple will be seamlessly integrated. The greatest security threat to the iPhone, according to Mehta, will be it's own popularity. I know it won't silence the critics but hopefully the drone of "Macs are only secure because Windows is a bigger target." will lose a few decibels. Unless, of course, the iPhone is bugged by as many security flaws as Windows and Internet Explorer have been, but my opinion is that it would be almost impossible to catch up to the lead Internet Explorer has.
Further on Gartner's list
Lack of support from major mobile device management suites and mobile-security suitesThose suites are designed to prop up security that has been omitted from existing smart phones. The iPhone, being based on Mac OS X will most likely support many of the same security features and management suites that Mac OS X desktop and laptop computers currently enjoy. There is simply no need for anything beyond what already exists.
Lack of support from major business mobile e-mail solution providersBy this I presume they are referring to lack of support from RIM and their existing infrastructure for Blackberry. Why would Apple want or need that in an iPhone ? The iPhone automatically connects to any open wireless network and handles email over standard (as in IEEE standard) protocols. If secure communication is required, the iPhone supports all the appropriate IEEE standards for that as well. There's no need for a dedicated, private network when you can just encrypt your communications and send them over the public internet.
An operating-system platform that is not licensed to alternative-hardware suppliers, meaning there are limited backup optionsLet's split this into two parts: The OS is not licensed to alternative hardware suppliers... so what ? What's the problem with this ? There isn't another hardware manufacturer that can make iPhones and even if there were, Apple sells hardware; they don't want just anyone else to sell the same hardware just so they can stick Apple's OS on it. It would cheapen the whole experience, and I'm not talking about the money here. The second part makes even less sense; how would licensing the OS to other hardware manufacturers make available further backup options ? There are already backup options apart from syncing your contacts, appointments and emails on to a computer. All these protocols are open and Apple's iSync allows you to write plugins for backing up whatever you like. Managing backups just isn't a technical problem, it's a people problem. Making backups easy is much more likely to succeed than having a plethora of backup options.
Feature deficiencies that would increase support costs (for example, iPhone's battery is not removeable)This is the first real complaint, but it's not a new one. People have been complaining about iPod batteries since they were first released to the public. Not being able to remove the battery has meant that many people had to send their iPods back to Apple to have them repaired and that is probably going to be less acceptable with a smart phone. Many people can barely live without their phones for the 8 hours it takes to get back home and recharge it after forgetting to charge it the night before. Smart phones would be even worse. Apple must be fairly confident that they have solved their battery issues but I predict lots of publicity for even a single failed battery in the first month.
Currently available from only one operator in the U.S.Definitely a real complaint and one that would cause me to postpone buying one if I were in the US. I predict this will change very shortly and people who have bought an iPhone now, before other carriers come on board and the prices drop, will regret being early adopters. Maybe Apple will offer rebates or free upgrades to people who purchased an earlier, inferior product but in the past they have only done this for purchases in the month prior to the announcement/release of the new scheme. Some people will be left out in the cold.
An unproven device from a vendor that has never built an enterprise-class mobile deviceBring on the marketing-speak and weasel-words! What is the MacBook Pro ? Is that not an enterprise-class mobile device ? What is the iPod ? What is an enterprise-class mobile device ? What makes you think that a vendor that hasn't released an enterprise-class mobile device are incapable of releasing a hit on their first time ? The iPhone was labeled "unproven" because it hadn't been released at the time they wrote their article. What Gartner were implying was that Apple are an unproven company which is clearly false. Apple have been around as long as Microsoft and IBM, they have been through good times and bad, as have both Microsoft and IBM, and they have survived. Now they are gaining serious traction amongst home users who love Apple products because they look good, just work and are fun to use. We are already seeing home users transition to business users and expect their computers to continue looking good, just working and being fun to use, even when they are being used for "work".
The high price of the device, which starts at $500$500 is expensive, however I have already stated that I expect this price to drop in the near future. This has always been Apple's strategy; to release a product that seems expensive to start with but is so insanely good that the product you left to try out Apple's product seems dull and unexciting afterwards. In the end you realise that you pay more and get more. It's up to each individual person to decide whether the extra price is worth what you get.
A clear statement by Apple that it is focused on consumer rather than enterpriseApple have never shied away from the enterprise. Believe me that the XServe RAID is not something that you would want in your living room. The iPhone, like the iPod is primarily designed for home consumers, not business consumers and yet Apple know that most people are both. Where I work, several of the people in my department have Apple laptops, most of them have iPods and I suspect that all of them would jump at the opportunity to use an Apple desktop instead of a Windows one every day if they could. (Not that my company doesn't support Macs... it just seems that you only qualify for one if you are an "arty" type and hence a Sysadmin who uses a terminal emulator all day, every day would be much better off with PuTTY than Apple's Terminal. Hmmph !) I would be extremely surprised if my boss didn't want to trade in his Blackberry for an iPhone. The iPhone will integrate into a corporate network as an extension to user's computers and the first people to get one will be the CTO and his team probably because the CEO already bought one and they know they're going to have to support it pretty soon.
Most handheld devices come with easy-to-use tools that enable rapid interfaces to business systems. When end users install such tools, they effectively 'punch a hole' through the enterprise security perimeter--data can be moved across applications to personally owned devices, without the IT organization's knowledge or control.This problem is not limited to iPhones. iPods, any MP3 player, USB thumb drives, laptops, mobile phones, CD burners... even floppy disks. All of them can be used to take sensitive data out of the corporation's control. If your security department don't want third-party applications installed on their computers, lock them down so it isn't possible but this alone will not stop data leaks. The only way to keep sensitive data secret is to limit access to the data. Most of your organisation should not have direct access to sensitive data. Those that do have access should have training about how to identify and handle sensitive data. Banning iPhones from your network is not going to help stop data leaks.
The article is misguided and seems to be more than just a little self-promoting. The more FUD that is spread, the more that corporations believe that they need consultants to understand it all. So it is always in the consultant's best interests to spread FUD or have FUD spread for them. This is FUD, pure and simple and it doesn't wash.
Galumph went the little green frog one day.
8am, 9th June 2007 - Geek, Interesting, Web, Developer, Sysadmin It's funny what you can discover when you analyse your web server logs properly. There are all sort of things happening out there on the net and some of those things happen may to you, even if you aren't aware of them.
It's funny what you can discover when you analyse your web server logs properly. There are all sort of things happening out there on the net and some of those things happen may to you, even if you aren't aware of them.
A couple of days ago, someone visited this very site in search of lyrics to a campfire song that I haven't heard anyone sing in nearly twenty years. How do I know this ? Well, if you do a Google search and your browser passes the referer string they way it should then the site you end up on can tell what you searched for. It's not just Google either. Many search engines support the same feature. This guy searched for we all know frog go ladadadada lyrics which returns precisely one page... mine. I'm not really sure why my page is the only result for that particular search but it does have the word frog on it and I appear to use the word we quite a lot. Just because I'm a helpful sorta guy, I would suggest that searching for galumph went the little green frog one day lyrics is probably going to get you much better results than your original search.
The most common search term that people use to find my site is "Ladadadada" but some others include "instant mee goreng", "co_conspirator", "noodly", "JAILBIRD GIFS", "gauma camping", "pizza pictures", "finish the sudoku", "can't get enough of croatia", "nebakanezer", "hippomoo newcastle", "EU PASSPORT lane". Strangely enough, MSN Live search only ever seems to direct people to my site who were searching for drugs. It's most likely that these are actually bots, trying to use the referer field to insert that search somewhere on my page and then hoping that I will do a search for a drug I haven't heard of and then want to buy it. It seems a little subtle for your average spammer. I have also received just the one referral from Ask.com. This person searched for how to open tamper proof tags and once again, there I was on the first page of the search results.
Then there's the guy who keeps trying to add comments to my blog. He loads one of the blog pages and then somewhere between one and ten seconds later he attempts to post a comment. There's more weirdness involved here however; any pair of requests (blog page then comment adding page) seem to come from the same browser but later, often on the same day, he will request the same pair of pages using a different browser and usually a different OS. So far I have seen 43 different user agent strings from the same IP address exhibiting the same behaviour. 13 different operating systems including Windows NT 5.0, Windows NT 5.1, Windows NT 5.2, Windows CE, Windows 95, Windows 98, WinNT4.0, Windows XP, RISC OS, WebTV OS, Mac OS 9, Mac OS X, Ubuntu and some other version of Linux. Some of the operating systems were in Russian and some in German. I have also seen 20 distinct web browsers including IE 3.02, IE 5.0, IE 5.5, IE 6.0, IE 7.0b, Opera 5.0, Opera 7.54, Opera 8.0, Opera 8.5, more versions of Firefox than you can poke a stick at (all counted as Firefox), Sylera, Galeon, K-Meleon, Phoenix, Spacebug, Minefield (all of which are builds of Firefox), Omniweb, Acorn, AOL 9.0, WebTV. After all this monkeying around with user agent strings, whatever script is actually creating all these requests isn't even behaving like a real browser. Firstly, unlike a real browser, it doesn't request the supporting parts of the page such as the stylesheets and images. Secondly, it doesn't resolve the form action base URL properly and hence all these comments end up going to a 404. In other words, whatever stock pumping / drug promoting blog comment spam he's trying to insert into my page, it's not working and he still hasn't noticed.
Like I always say: it takes all sorts to make this crazy world.
A tale of duelling GRUBs and boots.
8am, 26th May 2007 - Geek, Linux, Sysadmin Last night I finally coerced GRUB into doing what I wanted it to do. It's not that GRUB was particularly stubborn but more that it had a particular place that it liked to look for it's instructions on what to do and wouldn't do anything at all if it didn't find them in that place. Of course, no one tells you what this file is called... you don't really understand GRUB until you have searched half the internet trying to figure it out.
Last night I finally coerced GRUB into doing what I wanted it to do. It's not that GRUB was particularly stubborn but more that it had a particular place that it liked to look for it's instructions on what to do and wouldn't do anything at all if it didn't find them in that place. Of course, no one tells you what this file is called... you don't really understand GRUB until you have searched half the internet trying to figure it out.
Let me start from the start. I'm installing Linux because I have a low spec box (650MHz, 128MB, 16GB) and I think I can get better performance out of a tightly controlled Linux installation than a sprawling, all-encompassing Windows XP installation. Jane, however, has a fear of Linux, possibly caused by some sort of Linux based trauma while she was at University and hence I can't get rid of Windows just yet. It would be nice to install Ubuntu and just be done with it but unfortunately the two different versions of Ubuntu I have tried both require more RAM than I have. They would both boot from the Live CD if you had about half an hour to spare but as soon as you tried to do anything more complicated such as opening a program the system would grind to a halt. Hence I settled on Damn Small Linux, a distro designed for it's small size and low reqirements while still being flexible enough to grow into a full distribution once installed. I could have my cake and eat it too !
After burning the LiveCD (it seems such a waste that only 50MB of the CD was actually used) and throwing it in my computer, it booted straight into a desktop that was only using 18MB of RAM. Even browsing the Net with Firefox I was still only using 33MB. DSL looked like it was going to fit into my tight RAM requirements quite well. I told it to install itself to my hard drive and then looked up a tutorial on how to dual boot Linux and Windows, having never done that before.
Inevitably, you will end up on the first link from Google for "dual boot Linux Windows" which is Ed's software guide on Linux. Unfortunately, Ed's guide seems a little out of date and not all that accurate. He suggests using fips for your partitioning needs but the link he supplies is no longer current. I found that burning a gparted live CD provided more than just the best tool money can buy for free. The particular CD I burned has Grub installed with about as many options for booting as you can imagine, so once you have started messing around with GRUB and can't boot your own system any more, you can still put in the gparted CD, load GRUB and tell it to boot "The first partition from the second disk" or wherever your favourite OS is. His instructions also seem convoluted and unnecessary. In the end he seems to be using the Windows boot loader to give the choice between loading Windows normally or loading GRUB which will then load Linux. My final result was a little different. I loaded GRUB from a 40MB boot partition and then gave GRUB the choice between Linux and Windows. The advantage of this way is that the process of getting it all working is actually less complicated than Ed's instructions. The most useful guide to GRUB (and hence dual booting) I found was GRUB from the ground up from Troubleshooters.
Now, for the list of gotchas and caveats. Firstly, I used gparted to shrink my Windows partition by 40MB and move it to the right so I could fit a 40MB partition in before it. The reason I did this is because of that famous 1024 cylinder limit. I don't know if my computer can boot from beyond the first 1024 cylinders but I didn't feel like taking the chance. Linux was going to be on a seperate physical drive anyway so I would need a boot loader on the first drive (The BIOS calls it the C: drive.) to load Linux from the second. This took about two hours for a 50% full 16GB drive. One for a read-only test and one for the real thing. Your mileage may vary. I also noticed some flags you could set for each partition in gparted but while reading Ed's guide I was a little reluctant to mess with them because he makes it sound like you'll need to reformat everything and re-install if you screw up your MBR. My computer persistently kept on booting into Windows until I changed the "boot" flag from the Windows partition to my brand new boot partition. It seems obvious now but it just goes to show how a little knowledge is a dangerous thing.
Once I had changed that "boot" flag, I was presented with the GRUB command line when my system started up. It looks scary but it's not really all that bad if you have used the Unix command line before. You can use it to interrogate your hard drives and search for files (such as the Linux kernel) or figure out what hard drives you have or, if you're feeling wild and rebellious, you could use it to boot into one of your available operating systems. Until I figured out the GRUB configuration file I was booting Linux by typing three commands at this boot prompt every time I restarted. The commands I typed are explained in detail on the Troubleshooters page I linked to earlier and are included in my sample GRUB menu file at the bottom. The first command tells GRUB where it can find the rest of itself. GRUB's first stage can only be 512 bytes and if it's doing anything more complicated than handing control over to Windows then it will need to load some more code. root (hd0,1) refers to the second partition (,1) of the first hard drive (hd0) and this is the location of GRUB's stage 2. The second command kernel /boot/linux24 root=/dev/hdb5 tells GRUB where to find the Linux kernel (kernel /boot/linux24) and where Linux should mount it's own root filesystem from when it loads (root=/dev/hdb5). If those two commands print confirmation messages rather than error messages then the third command is simply boot.
To make things a little easier, you can tell GRUB some of these commands in advance and group them together under convenient labels such as "Windows" and "Linux". If you are installing a new Linux kernel you can set up a new group called "Linux with new kernel" and give it a different kernel statement. There seems to be some confusion over whether these instructions should go in a file called grub.conf or a file called menu.lst. I found that grub.conf didn't work for me no matter where I put it but once I put the same contents into a menu.lst file, it worked straight away. Below is what I have in my menu.lst file.
timeout 10The location of this file and others needed by GRUB may cause some confusion. It is common to mount your boot partition under /boot on a Linux system however it is not strictly necessary to mount it at all after you have created it. In fact, you can create it without mounting it but I wouldn't recommend that until you are an expert. The confusion arises because when GRUB mounts your boot partition, it doesn't mount it as /boot. GRUB will mount it as / which means that any path you specify to GRUB that has /boot at it's start will not work. Some people suggest using a symlink in your boot partition that looks like this: (boot -> .) This symlink will allow the same path to work for GRUB when the partition is mounted at / as for Linux when the partition is mounted at /boot. Another option would be to install all of GRUB's files in /boot/boot/grub/ and symlink (grub -> boot/grub) to make Linux do the symlink chasing rather than GRUB. In either case, if GRUB can load then you can put your files (grub.conf or menu.lst) in the same place as GRUB's stage1 and stage2 files and feel safe in the knowledge that GRUB will find them.
default 1
title Linux
root (hd0,1)
kernel /linux24 root=/dev/hdb5
title Windows
rootnoverify (hd0,0)
chainloader +1
I hope my little story has made it easier for you to get your system dual booting or simply booting at all.
Distribution and layers
8pm, 2nd May 2007 - Geek, Interesting, Web, Security, Developer, Sysadmin Lately, I've noticed that the application of layers and distribution to a great many things seem to improve nearly every aspect of the thing in question. It may seem obvious when it's pointed out but for me, at the time, it was the application of a well known principle in computer science to areas outside computer science and the astonishment that the principle continued to work.
Lately, I've noticed that the application of layers and distribution to a great many things seem to improve nearly every aspect of the thing in question. It may seem obvious when it's pointed out but for me, at the time, it was the application of a well known principle in computer science to areas outside computer science and the astonishment that the principle continued to work.
I think I was first exposed to distribution when I discovered the distributed.net project. The idea was that sometimes a problem that would take one person an entire lifetime to solve can be solved by 1000 people in 1/1000th of a lifetime. When a problem is able to be split up like that (it is said to be parallelisable or distributable) then it makes sense to share the workload out over an appropriate number of people to be able to finish the job on time. In the case of distributed.net, a problem that was supposed to be unsolvable in any practical amount of time (decrypting an encrypted message) was actually solved in 22 hours!
Improving the time to solve a problem by distribution is not only applicable to large problems that can be split up into chunks but, not surprisingly, also to large numbers of small problems. Web servers are a very commonly used example. You may request a web page from a server and receive a response - your web page - yet when you make the same request later, it may be served by a completely different server. The magic behind the scenes is usually a load balancer in front of a number of web servers. The load balancer is designed to make sure each of the web servers is doing an appropriate amount of work and should be invisible to the end user.
There are several advantages of using a load balancer in front of many web servers rather than buying a faster, more expensive machine that can handle the same load all on it's own and the first one is price.A lot of almost nothing adds up to something.
A system is more reliable if it has no single point of failure. As a website grows it often starts with just one small web server but eventually this solitary web server won't be able to keep up and at this point it is much cheaper to buy a second small server with a load balancer than to buy a new server with twice the capacity and throw the old one out. Over all, you may have spent the same amount of money but the spending was small when your website was small and grew in proportion to your website. Other advantages can be even more compelling - one of my favourite benefits of distribution is reliability. If you have 10 web servers and one of them crashes, each of the other 9 will have to do 10% more work but your website will keep on working. The failure will not affect your visitors.
The two principles at work here (with the distributed.net project and the web server balancing) are that a lot of almost nothing adds up to something and that a system is more reliable if it has no single point of failure.
Layers are really just a specialised application of distribution where all of the elements are chained together and each element in the chain does a slightly different job. A job is only passed along to the next element in the chain if the current element of the chain can't complete it. Often, the chain is ordered so as to optimise it's own efficiency.
To continue with the example of the web servers, in order to speed up the response times of web servers, web masters use caching. Caching involves taking the result of a long, slow process and remembering that result. The next time somebody asks us for the result, we just hand them the copy we remembered (our cached copy) rather than calculating the result again. Caching usually improves access speed and reduces calculation time at the expense of using up more memory however as memory is often quite cheap, this trade-off is usually worthwhile. Caches usually have rules about how long they are allowed to remember a certain result so that they don't continue to remember a result that is incorrect or stale.
Caching is broadly applicable and can be implemented in many places within the system. The SQL server can cache results of certain queries so it doesn't have to calculate them again when the web server requests and the web server can cache it's copy results of the same queries so it doesn't even have to ask the SQL server for them. Sometimes, in front of the web server, there is another specialised web server called a proxy server which can also cache the page generated from the SQL queries by the web server so that it doesn't have to generate that page again. As Caching happens closer and closer to the source of the request, the advantage grows larger and larger. Sometimes your ISP will cache pages or parts of pages and not even ask the website to send it's copy to you but rather just send their own. Your own computer even caches pages and parts of pages you have requested so that if you request something a second time, it already has it and just gives it to you straight away. In this way, a request for a web page can be distributed over many different computers and the result is a much faster page on your screen. The other main advantage of distribution still applies here; if the SQL server crashes or the web server crashes, you may not even be aware of it because your entire page was served from a cache closer to you than either of those two servers.
Layering applies to more than just caching however. Spam filtering works quite well with many layers. Your ISP probably employs many layers of filters in order to prevent spam from reaching your inbox. Acme.com has a very good write-up on filtering spam using layers. One nice thing about these layers of filters is that you can use the results of later filters to modify earlier filters in order to reduce the total workload. Because the filters are applied in an optimised order, if a job is filtered at an earlier level it actually takes less work to achieve the same result than if it were filtered at a later level. This is still true even when you ignore the workload all of the filters in between that don't even filter the job. Caching can be seen as a series of filters that are filtering a request for a web page. As soon as one filter can resolve the request it does so and doesn't pass the request any further along the chain.
Another area where layering can create advantages is security. This is a principle often known as defence in depth. (Defence in depth also covers other areas but for the purposes of this discussion, it means layers.) In this case, the layer is usually not created in front of the existing layer, but behind it. For example, you might place a firewall at the external perimiter of your network to restrict access (layer 1) and then also place firewalls on each of your hosts within the network (layer 2). It may seem, if the firewalls were configured identically, that anything that made it through the first layer would also make it through the second layer but it is not so. If an attacker avoided the outer firewall by exploiting an unsecured wireless network set up by an employee within the building, then the firewalls on each host would be the only thing protecting the data contained within. Having said that, there is nothing that requires the firewalls to be identical. In fact, you should make each firewall as restrictive as possible (but not more so) on a case by case basis. Layering improves security because an attacker has to break each layer of security seperately and if any layer fails, the next likely will not.
So far, these examples have been all very computer related but thinking about them made me wonder if the principles involved might apply to areas not related to computers. It didn't take long for me to find some. Power generation is a good one. If every home has some alternative source of power generation - a wind turbine, solar panels, whatever they like - then the advantages of distribution take hold. The power station has reduced load and if a disaster strikes bringing the power lines down it affects fewer people and those not as badly. People can grow their own vegetables too. This means reduced load on farmers (and the land) and more reliability if the farmers are unable to deliver the vegetables for some reason.
Layering applies quite well to call centres. When your phone is first answered, it's just a computer that tries to figure out what you want, answer you if it can and direct you to the appropriate person if it can't. The first layer is cheap - one computer can handle hundreds of simultaneous connections - and the second layer often works the same way. The first humans you talk to will probably be paid minimum wage and have a book of common questions and answers. If they can't solve your problem, up the chain you go to the more highly-paid, more highly skilled who can solve the few problems that make it all the way to them. These guys could solve any problem that came to them but it's much cheaper and more efficient to filter out the easy stuff before it gets that far.
Physical security is enhanced by the application of layers. A guard at the door of a casino might stop most miscreants getting in but guards patrolling the floors at random could find them even after they have entered and could certainly help stop a robbery in progress. Casinos are such tempting targets that they need to have layer after layer after layer. Staff training, CCTV cameras, areas with different access controls, strong authentication methods for building access, rotating the floor staff regularly, seperating in house cash across several safes rather than just one... the list goes on.
I'm pretty certain that layers and distribution aren't going to solve all of your problems, but there's a good chance that a lot of them can be made less of a problem by using one of these techniques. See where you can fit them into your life.
Dave's rebuttal of Macrovision's response to Steve Jobs' open letter about DRM in iTunes
9am, 22nd April 2007 - Geek, Rant, News, Humour, Apple, Hardware, Legal On February 6th this year, Steve Jobs wrote an open letter to the world talking about his views on DRM. He called it "Thoughts on music". Some time later, Fred Amoroso, the CEO & President of
Macrovision (pictured) wrote his own open letter in response to Steve's. Since all this "open letter" writing is really just a bunch of blog posts (CEOs don't have blogs - they just write something and get their web team to stick it on the home page for a while.) I thought I'd make my own in response to Macrovision's, mostly because it's just so wrong... about everything.
On February 6th this year, Steve Jobs wrote an open letter to the world talking about his views on DRM. He called it "Thoughts on music". Some time later, Fred Amoroso, the CEO & President of
Macrovision (pictured) wrote his own open letter in response to Steve's. Since all this "open letter" writing is really just a bunch of blog posts (CEOs don't have blogs - they just write something and get their web team to stick it on the home page for a while.) I thought I'd make my own in response to Macrovision's, mostly because it's just so wrong... about everything.
I would like to start by thanking Steve Jobs for offering his provocative perspective on the role of digital rights management (DRM) in the electronic content marketplace
Just a minor quibble here: you're placing words in Steve's mouth. His letter was about DRM in music sold online, specifically in the iTMS for iPods because that's the area he has reliable figures for.
While your thoughts are seemingly directed solely to the music industry, the fact is that DRM also has a broad impact across many different forms of content and across many media devices. Therefore, the discussion should not be limited to just music. It is critical that as all forms of content move from physical to electronic there is an opportunity for DRM to be an important enabler across all content, including movies, games and software, as well as music.
Well done for spotting that. It must have required a serious application of time to see through the veil. However, did you go on to ask yourself why Steve may have limited himself to the music industry ? It's not because he only dislikes DRM on music. It's because he sells 80% of all digital music players and hence has a much bigger stick to beat the music industry with. Steve picks the fights he can win. It now looks like he's talked EMI into a truce and that should help convince the other three of the big four. Once they are on his side and can see the benefits to themselves of not alienating their own customers then my prediction is that Jobs will go after online video. It's not a big stretch to see the connection between iPod Video, Apple TV and the iTunes Music Video store.
I believe that most piracy occurs because the technology available today has not yet been widely deployed to make DRM-protected legitimate content as easily accessible and convenient as unprotected illegitimate content is to consumers. The solution is to accelerate the deployment of convenient DRM-protected distribution channels - not to abandon them. Without a reasonable, consistent and transparent DRM we will only delay consumers in receiving premium content in the home, in the way they want it. For example, DRM is uniquely suitable for metering usage rights, so that consumers who don't want to own content, such as a movie, can "rent" it. Similarly, consumers who want to consume content on only a single device can pay less than those who want to use it across all of their entertainment areas - vacation homes, cars, different devices and remotely. Abandoning DRM now will unnecessarily doom all consumers to a "one size fits all" situation that will increase costs for many of them.
Once again, you haven't asked yourself the next question: "Why ?" Why hasn't the technology been widely deployed ? Well, Steve went into some detail about this in his letter but I'll summarise it here: DRM involves keeping secrets from the consumer so that only you can control what they can do with their music. The more people know your secret, the more likely it is that the secret will leak out and render the DRM inneffective.
Let's also tackle this "renting" myth. Some consumers may only want to listen to their music on their iPod and never on their computer and never on their home entertainment system and never in their car. Where is the cheaper option for this hypothetical consumer to purchase their music ? Buying a whole album from any music store is not much cheaper than buying the same album on CD. People aren't getting music more cheaply because it's only playable on two or three devices but rather because it's cheaper to only buy the two or three good songs from the album and it's much more convenient to download music than to drive to a store, purchase, drive back and rip the CD to mp3 using your computer. It becomes much more expensive if, later, you decide that you would like to listen to that album in your car after all and have to buy it again. The iTMS allows you to transfer your music to five different devices but the rub is this: they still have to be able to decode the DRM, which means they must be made by Apple. Your computer and iPod, your girlfriend's computer and iPod, your Apple TV... and that's it. If you have another device you would have to de-authorise one of those first five to use the new one. If you can't do that because, for instance, your iPod was stolen or your computer died, then you are sorely out of luck.
Lastly, DRM costs Apple money. Money which they ask the consumer to pay. The money goes to the engineers who have to create the DRM software and the sysadmins who have to deploy it. It goes to them all again when someone breaks the current DRM scheme because, clearly, the consumers don't want it and the engineers and sysadmins have to create a newer, better, stronger one. DRM also increases the bandwidth costs for Apple, the consumers and everyone in between.
So DRM increases costs, increases hassle, restricts what you can do with your music and, in some case, forces you to buy the same music again. Given all this, I think consumers would prefer the "one size fits all" model.
Well maintained and reasonably implemented DRM will increase the electronic distribution of content, not decrease it. In this sense, DRM is an important ingredient in the overall success of the emerging digital world and especially cannot be overlooked for content creators and owners in the video industry. Quite simply, if the owners of high-value video entertainment are asked to enter, or stay in a digital world that is free of DRM, without protection for their content, then there will be no reason for them to enter, or to stay if they've already entered. The risk will be too great.
Generally, the producers of content would love to enter a the digital world. The thing is, the producers are not being asked. It's important not to confuse the music labels with the content producers. Sure, the music labels supply the up-front money and their expertise in finding the right people for the job and distributing the final product but the main thing signing with a music label will do for you is get you noticed. Some "talent scout" from a music label decides who is going to be the "next big thing" and promotes the living heck out of them. Every radio station in the country receives a free CD with their best songs on it. They get appearances on TV talk shows, ads on the subway, gigs at major music festivals. All of the stuff they wouldn't have been able to get on their own. In return, the music label gets their souls. Actually, they just get a really big IOU and a commitment to create four more albums and, of course, the copyrights to the songs on the album. The artist's souls usually just wither and die. Having just spent enormous amounts of money on a couple of kids who they hope will write music that the public will like and will sell enough records to recoup their costs, the record labels now want to make as much money as they can from the sales of these songs. Very little ends up going to the actual artists. So the artists would be better off if they could, somehow, get popular without needing a record label to pay every influential person in the country to say "Hey, look at these guys. Aren't they cool ?" That's where the Internet comes in. The Internet is so big that even the smallest of niches have thousands of people crammed into it. Better yet, your distribution costs don't scale with the distribution of your audience, they scale with the size of your audience. i.e. As your costs get larger, your income gets larger to match it. If you find your niche - and trust me, there's one for you - then there will be enough popularity to keep you going.
So, after all that, do the artists want DRM ? No. Artists want to be recognised for their artistic merit and to be compensated enough to continue performing their art. Artists don't want to squeeze every last penny from their appreciative audience, they would rather have an entire crowd singing along to their songs at a gig without having already paid for the songs at home than to have no one at the gig because they couldn't afford it. In the end, artists are what matter. They will keep right on producing songs with or without the music labels and they will find a way to get those songs to their audience. If DRM hinders that process, the process will drop DRM and, if needs be, the music labels who promote it.
I agree with you that there are difficult challenges associated with maintaining the controls of an interoperable DRM system, but it should not stop the industry from pursuing it as a goal. Truly interoperable DRM will hasten the shift to the electronic distribution of content and make it easier for consumers to manage and share content in the home.
If there are problems with a technology then the industry should look for alternative methods of achieving the same goals. Ignoring the reasons that Steve mentioned that DRM cannot be interoperable, a truly interoperable DRM may hasten the shift to electronic distribution (however, it certainly does not make it any easier for consumers to manage and share content in their own home) but at what cost ? Going down the DRM route now will commit the labels and distributors to that route in the future. Consumers will be stuck with it until they can bypass the labels entirely. The more investment they have in DRM the more they will invest in flogging the dead horse, hoping that it's not really dead... just sleeping. DRM is pining for the Fjords.
Towards the end of Macrovision's response, Fred takes the liberty of assuming that if you have read this far then you must agree with him and will believe any old bald-faced lie he cares to spout. He offers to absorb Apple's FairPlay into Macrovision's own DRM offering and hence make all songs "just work" on all music devices everywhere. He likens the introduction of DRM to the introduction of television and the PC into the home. Yes, truly a revolution in entertainment. Finally, he repeats the one actual point from the article, the fallacy that he wants us believe: that DRM is good for us because without it, there will be no music, no video, no games, no software of any sort. I don't think anyone will be fooled.
Much ado about DRM
12pm, 14th April 2007 - Geek, Rant, News, Apple, Legal
Apple makes an announcement.
I know I'm weighing in a little late for the debate on Apple and EMI's announcement that they are dropping DRM for songs sold on the iTunes Music Store but I've never been one to jump in early and voice my opinion before I've fully formed it. I was kind of hoping that some of the other labels would follow suit and maybe even some of the other online music stores would jump on Steve Jobs' bandwagon and publicly renounce DRM before I sat down to write.Dave reads between the lines.
Firstly, about the pricing/quality model: it's a crock. There is no need to tie DRM (or the lack of it) to the quality of the encoding and therefore the price of the song. I suspect that EMI required this so that if it didn't work out they would have an exit strategy that wouldn't leave too much egg on their faces. They can simply claim that consumers didn't want higher quality music for higher prices and then go back to their old, low-quality, low-price songs and pretend that DRM had nothing to do with it. Many people wouldn't buy that ruse but PR-wise it would look better than "We experimented with non-DRM songs and didn't like it so we're putting DRM back on everything."Too many choices.
Apple are offering whole albums at the higher quality with no DRM and at the same price as before but the point of the iTMS is that you don't have to buy the whole album to get the songs you like. Most albums have some filler on them and many albums only have one or two good songs. As a consumer, you are now caught in a difficult place: do you buy just three songs for 99p each (£2.97), or the same three songs with DRM at a lower quality for 79p each (£2.37) or the whole album at the higher quality, without DRM but with songs you will not like for somewhere around £8 ? With more choice comes more confusion. I sincerely hope they drop the DRM from the lower quality tracks once the trial is over and make the choices less confusing for the average consumer. Remember, of course, that you can remove the DRM from downloaded songs for a cost of about 1-2p per track plus the time taken up in the process simply by burning them to a CD and then re-ripping back to mp3 (or aac or wmv or ogg-vorbis... whatever tickles your fancy.) but for most people this effort is more than the result is worth.Good for iPods.
Steve Jobs must have known that he was getting close to announcing this deal with EMI and wrote that famous open letter partly to deflect criticism from the iTMS but more importantly to have his views about DRM on the record before the deal went public. That way everybody gives Apple (and Steve Jobs) the credit for removing DRM. Even if other labels and other music stores had deals like this in the pipeline, even if they get them out the door first, Apple will still be seen as the innovator because Steve Jobs said he was against DRM before anyone else. Besides all the good publicity, the deal itself provides iPod owners with a greater freedom of choice. I personally know someone who was given an iPod as a present no more than two months ago who traded it in for another brand because "She could only buy music from the iTMS." Ignoring the fact that you can put all of your existing non-DRM MP3s on it quite happily, it now won't be long before you can buy songs from any music store and play them on your iPod. I may be going out on a limb here but I think that this will be good for iPod sales. Had my friend received her iPod a few weeks later she may have simply been happy with it. It is still a bit of a gamble for Apple. Without Apple's FairPlay DRM you can quite happily switch to another music player and take all of your songs with you. This leaves Apple competing with all the other players based on the quality of the player itself, rather than having users of the iTMS locked in to iPods because no other player can play FairPlay encoded tracks. That is, however, an arena in which Apple have already shown they can compete.Bad for WMA.
Now that music stores can sell EMI tracks without DRM, non-iTMS music stores can now target the iPod. They've been wanting this ever since the iPod snaffled a majority share of the portable music player market. But the iPod doesn't play WMA and the only thing forcing them to stay with WMA is it's DRM capabilities which the labels require before they'll license the music. Without that requirement, music stores are most likely to choose MP3 or AAC and switch all of their music. They would be shooting themselves in their feet to do otherwise. Since the iPod supports both of those formats, every non-DRM track sold on other music stores will now play on an iPod. Sure, the Zune supports MP3 and AAC but it's WMA that Microsoft really wants on their Zunes. They make far more money out of licensing WMA to music stores and music device manufacturers than they will ever make out of selling the Zune.Little by little.
I know this isn't a win for consumer rights. It' a compromise. We want all music to be ours once we have purchased it; to do with as we wish. The music labels want to make as much money as they can and they are using copyright law to achieve this. They are doing everything in their power to make every one of us pay for every little service they provide, even if it is as little as being allowed to listen to the same song on your home sound system, your computer and your portable music player. If they could, they'd be happy to see you purchase that song three times to achieve that Utopian dream. So we fight and they fight and the result is somewhere in the middle. Some people would say that we should hold out for more. That we shouldn't accept this price hike for non-DRM tracks and we should demand that we get all our tracks without DRM for the same price as before. I say that these people will never be happy. A step forward is a step forward. Now we start fighting again and when we win the next battle - even if it is still only another compromise - we will be another step closer to what we really want. And I'll be ever-so-slightly happier about it.It's all relative
8pm, 29th March 2007 - Geek, Rant, Interesting, Philosophy How do you put a value on taste? How can you say "I give that meal 83% and the dessert 94%"? How can you know that there isn't a meal out there somewhere that's twice as good as the one you just had ?
How do you put a value on taste? How can you say "I give that meal 83% and the dessert 94%"? How can you know that there isn't a meal out there somewhere that's twice as good as the one you just had ?
The trouble is that taste is a relative measurement, not an absolute measurement. Most measurements we consider useful are absolute measurements such as "That meal cost £12." or an absolute measurement expressed in relative terms: "That meal cost twice as much as the meal I had yesterday." but some things cannot be measured in absolute terms.
To illustrate, take Maurice Greene. Maurice Greene is fast. Some might say that he's the fastest man in the world. (Asafa Powell might disagree, having beaten Maurice's time over the 100m by two hundredths of a second on three seperate officially recognised occasions.)
Still, nobody can dispute that he's fast - but I'm faster.
How is this so? Well, I can jump on my bike and pedal faster than Maurice (or Asafa) can run. So Maurice is fast, and you would say that he's the fastest man in the world until you saw me on my bike. Now he's not the fastest man in the world, his top speed is only half my top speed! But why stop there? You can jump in your car and double my top speed again. Donald Campbell might seem fast in his Bluebird going at half the speed of sound but that that is only until you consider a manned space rocket which is going around 20 times the speed of sound as it approaches the atmosphere from outer space.
Speed is relative to the fastest (and slowest) you have ever seen. Until you have been in a rally car doing 200Km/h on twisty dirt roads then you will think that 100Km/h on the highway is fast - the fastest you have ever been - afterwards, it feels slow. This is rarely more pronounced that when driving in rural Australia and approaching a small town after having spent several hours with no speed limit and without even having to turn the steering wheel. Having to stick to 50Km/h all the way across the 2Km wide town will make you feel like you could get out and walk faster.
So today, when I was pondering the value of my lunch and determined that it was 30% more expensive than the alternative next door but 70% larger I figured this was a good deal. Then I started thinking about other determining factors and realised that although the taste of the meal I had today was definitely better than anything available next door, I couldn't say it was twice as good or even 25% better because to do so would be comparing both meals to the very best and the very worst meals I have ever eaten. That would be similar in comparison to lining Michael Schumaker and Lance Armstrong up on their respective machines and taking bets on which one would complete the 500Km course first. Of course, it would also be utterly meaningless to anyone who had not also eaten the same two (best and worst) meals that I had eaten and hence trying to explain to someone that this cafe was 3% better than the other one but on the scale I was using that actually represented a significant difference would be an exercise in futility.
Minimum wage: minimum job
11am, 25th February 2007 - Rant Lately I've had to deal with a lot of people in dead-end jobs who earn minimum wage. Mostly in call centres but also driving buses, guarding entrances to buildings, sweeping streets and behind counters at local newsagents, cafes, retail stores and pubs. The resounding impression I get from them is that because they are earning a minimum wage, they are going to do a minimum job.
Lately I've had to deal with a lot of people in dead-end jobs who earn minimum wage. Mostly in call centres but also driving buses, guarding entrances to buildings, sweeping streets and behind counters at local newsagents, cafes, retail stores and pubs. The resounding impression I get from them is that because they are earning a minimum wage, they are going to do a minimum job.
I've seen bus drivers who when asked if their bus stops at Hampstead station replied "No", even though they stop at the bus stop that is about twenty metres away from the official "Hampstead station" bus stop and is actually physically closer to Hampstead station. The passenger got off the bus and started walking away before I told her where the bus really went. I've also seen bus drivers reply "Yes" when asked if their bus goes to Finchley Road, even though they had already passed Finchley Road on their route and were currently travelling away from it.
I've seen cooks in the kitchen skip over the next meal on the list because they didn't understand what the wait staff meant on the meal docket and I've seen them leave a whole table's worth of food under the heat-lamps, drying out the meat and wilting the salad because one of the meals only had two mushrooms instead of three and none of the cooks had time to go out to the store-room and get some more.
I've seen all sorts of short-cuts by bar staff that would make you think twice before eating or drinking in their establishment. Even something as simple as not checking the glasses coming out of the dishwasher for orange pith and lipstick marks before putting them away or back in the dishwasher to using the same cloth to wipe out the ashtrays, wipe down the tables, wipe down the bar and polish the silver... in that order. Most of this would be solved with proper training, but these staff don't get training because they never stay long enough for the hygiene course to come around again and the reason they don't stay long enough is because they are earning minimum wage in a dead-end job; as soon as anything even slightly better comes along they move on.
The one that really gets my goat, however, are the people in call centres who don't even take the time to use their inside knowledge of their field to figure out what your problem really is and give you the information needed to fix it. As an example, I have recently made several phone calls to TalkTalk customer service (that's what they call it.) to try and figure out when my broadband service would go live. The first two I got through to reassured me that it would be February the 9th, just like it said on the website and in the letter they had sent me and amended that to "Real Soon Now" when I pointed out that today was the 10th of February. The third guy I got through to, not being satisfied that the others were doing their job properly, noticed that although the phone order had been created on the 5th of January, the broadband order had not been created at all! The other two I had talked to hadn't even bothered to look at my account. The funny thing is that now, because I expect the customer service to be so bad, I have to keep ringing back again and again until I get through to someone who does their job properly in spite of not being paid very much. I have to waste much more of my time, much more of the call centre's time and much more of everybody's patience in order to get what I want when they could reduce all of this wastage simply by spending a little more at the outset to ensure that I get what I want first time. In the end, that's what makes a company money - giving the customer what they want.
They took my shower !
10pm, 5th December 2006 - RantA few days ago, the people downstairs knocked on my door and asked if we could do something about the water leaking through their ceiling which was making it sag quite alarmingly.
Naturally, I agreed to call my landlord and ask her to do something about it, which I did the very next day. In contrast to what I expected, the landlord managed to have a guy around that very evening to assess the problem and see what he could do to fix it. He assumed that the problem was being caused by the shower and asked us not to use it the following morning. During the day, while I was at work, he came around and used a silicon sealant to go over the grouting underneath the showerhead. A poor job but one that would seem to suffice, particularly as we were planning on moving out of the house ten days after that anyway.
The problem persisted and the handyman came back and wanted to have another look at it. Unfortunately, he neglected to warn us of his visit and turned up at a time when Jane was actually in the bath. I declined his request to inspect the bath until such time as Jane was finished with it. He asked us not to use it again the following morning and said that he would have a professional in to look at it the next day. We rested easy, knowing that with our bathroom in good hands we could look forward to a long, hot shower every morning and no angry neighbours banging on the door, demanding that we stop showering.
The following afternoon, we arrived home to find a note duct-taped to the bath saying that we could not use the bath any time in the next 24 hours and that we could not use the shower again at all. We also noticed that the showerhead was missing. They had taken the showerhead with them to enforce our continued lack of cleanliness!
I suspect that this has solved the problem downstairs but the solution is totally unsatisfactory for us. If the shower is leaking, the correct solution is to plug the leak, not to remove the shower. A bath is a wonderful way to relax but not all that practical when trying to simply clean yourself before getting dressed and going to work. By the time the bath is run, I could have finished my shower and be on my way. We have no word yet on when they plan to restore the showerhead to it's rightful place but I suspect that their plan is not to even look at it until we have moved out. Moving out may come a litte sooner than we had originally planned. The new place has a much better shower and we are on the ground floor so there will be no neighbours to worry about.
Enough of my woes! I think it's time for a bath.
How different must a copy be before it is no longer a copy ?
10pm, 21st November 2006 - Geek, Rant, Interesting, LegalSome breaches of copyright are obvious, indisputable and illegal. The rest, however, fall into some sort of legal grey area where the infringer may feel that his use is fair, the infringee may feel that the use is not fair and the courts will have a hard time reaching a decision. Unfortunately, while the courts are not influenced by large wads of cash, they are influenced by smooth-tongued lawyers and lawyers are influenced by large wads of cash. Inevitably, companies with large wads of cash tend to look enough like winning the court cases or at least bankrupting the defendant that the defendant settles out of court for a sum that takes him or her up to the point, but not over, of bankruptcy.
So where does one draw the line between what is fair and what isn't ? A lot of press recently has put the focus on what they call a "perfect digital copy" however most of the copyright infringing works found on the internet are not perfect copies. A straight copy of a digital file is a perfect copy but files are nearly always changed in some way to make them more easily distributable.
A DVD is usually decoded from it's original format and re-encoded into DivX, XviD, H.264 or one of many other formats before being posted on the internet. Shorter movies are encoded as WMV, MPG or SWF. CDs are usually found encoded as MP3s. Stock photography will mostly be transformed from large, high quality TIFF or PSD files into much smaller JPEG files.
These files, when compared byte for byte with the originals are not just "not perfect copies", they probably don't even have a single byte in common! In a file that is seven million bytes long, that's significant. So is this still the same work ? Does it not infringe because it is not a perfect digital copy ? Well, no. Even though the bytes are different, if you play the movie or view the image or listen to the music using an appropriate piece of software the experience will be almost indistinguishable from the original work. The lawyers don't seem to have much trouble in convincing the court that this situation is in breach of copyright. One can assume by extension that any software you could write that may encode a file so that it does not resemble the original in any way is still of no use in avoiding copyright laws if the file can be decoded back into something that resembles the original when experienced in the same way as the original.
Fair use rights state that it is permissable to use a small part of the original work. I'm a little fuzzy on the exact details but the general gist of it is that when writing a review of a movie, you are allowed to include a still shot, when writing an article about a band, you are allowed to use the titles of their songs. It would not be fair use to show half the movie or list the entire set of lyrics. For that, you would need permission from the copyright holder. If it is fair use to post a short clip from a movie in your review of that movie, would it be considered a breach if you posted, say, the first five minutes and another blogger posted the second five minutes ? What if another posted the third five minutes ? How many bloggers are there ? Who could be sued if the entire movie was available online in seperate five-minute clips ? What if there was a piece of software available that could aggregate all of these parts and produce an entire movie ? Is this not, in effect, what bit-torrent does ? (In practice, bit-torrent users tend to have more of the file available than what would be considered fair use.) Does this make it all legal ? Does this make it all morally sound ?
Copyright law was designed to allow artists to maintain a time-limited, exclusive right over a work so as to encourage them to make more works of art. The term artist as used here enjoys a very broad definition which includes painters, novelists, musicians, composers, poets, photographers, journalists, bloggers and, of course, movie makers. It was recognised that considerable effort went into dreaming up an idea in the first place and bringing that idea to a point where it is deemed a work of art. This is traditionally the period where a starving artist starves. If a work is successful enough that people want to copy it, then the artist should be rewarded by being granted an exclusive right to sell (or do whatever he wishes with) that work. This is traditionally the period where the starving artist falls completely into his work, so bouyed by the very people loving his work and wanting more of it that he often forgets to eat and hence continues to be a starving artist. This is acceptable however, because the artist has what he needs. He has a roof, a pen and paper, a video camera, a guitar; he can continue making works of art as the copyright law intended him to be able to do.
These days, the actual rights to the work of art are often transferred to a corporation in return for enough money that the starving artist need not starve while creating that all-important first work. The corporations often do much more than just that, such as organising and bringing together all the people that can help create the work, setting up distribution channels, seeding the work to high-profile promotional figures so that it gets the attention it deserves and handling all the sales once the artist is popular. Do they then deserve the exclusive rights and protections that copyright law originally intended for the artist ? Well, yes. They help promote the cultural well-being of this world by supporting artists and the law should help them do this.
Unfortunately, greed then takes over and the corporations start abusing the law to make them even more money and deny that money to the artists. They use their money to pay lobbyists to influence the law-makers to change the laws so that the corporations can make even more money. They use their power to create an artificial culture of hits and misses where it is impossible for an artist to become popular without gaining to support of a corporation first. Support which usually entails signing over ownership of their work and often some number of future works to the corporation.
This begs me to ask the question again: where do we stand morally when choosing to circumvent the law by depriving an amoral, greedy corporation a small amount of money for a work of art they didn't even create ?
I sold my soul to make a record, dipshit,
and then you bought one.
Tool: Hooker with a penis.
As the cost of sharing popular works of art has come down, the incidence of piracy (the illegal copying and distributing of copyrighted works) has gone up. The corporations realise that their value in creating distribution channels and seeding works to induce popularity is diminishing and it has got them worried. They aren't worried about losing money to piracy, they are worried that the artists and consumers might realise that they don't need the corporations at all anymore.
Do youself a favour: find a good quality, unsigned artist and buy their work. It can be a painting, a CD or a film. Once the artists realise that they can promote themselves on the internet, distribute their works on the internet, find people with the skills to record and act in their works on the internet, sell their works on the internet and find popularity on the internet, they'll realise they don't need the middle-men at all any more.
Clever girl...
7pm, 17th November 2006 - Geek, Interesting, Web, Security, Sysadmin
Just when you've got one in your sights, the other two attack you from the side.
I was surprised a couple of days ago to find a significant number of entries in the slow queries log on one of our web servers. While looking through them we discovered that they were caused almost exclusively by someone doing a search for a fairly unusual search string. The search string looked like this: "<A HREF = "http://example.com">example.com</A>" which, as I said, is fairly unusual. What that represents, for all you non-web-geeks out there is the HTML code that would create a link to the site example.com and would look like: example.com. A strange thing to enter into a search box to be certain.
Why would anyone type that into a search box? My first thought was that it was referrer log spam, or some variation on it. The idea being that every request that is made to a website is stored in a log, and some websites publish those logs or the statistics from those logs as part of the website itself. These statistics can be visited by real users who may click on the link or by search engine robots which can increase the pagerank of the site in the link. None of our websites do that however so that seemed unlikely to be the motivation.
I realised quickly after this that the motivation was probably a little more clever, but clearly unscrupulous so we decided to block his IP address. Strangely enough he seemed to be coming from a range of IP addresses. A class-C range to be precise, and pretty much randomly at that. He also had a user-agent string of "Slurp". A quick reverse-DNS lookup and we realised that this was the Yahoo! search engine's robot crawling our sites and doing these searches and therefore that blocking the IP addresses was not a good idea.
So why was Yahoo! doing searches for random bits of HTML on our sites? The answer was found within another site, found via Google that had a large list of links that when followed linked to a search results page on some of our sites. The idea was similar to the referrer log spam but rather than creating a bot that had a link in it's referrer string, this one used search engine bots to attempt to insert links into our search results and then index those pages and potentially increase the pagerank of the linked site. It's unlikely to fool real users but they were not the motivation here; this was all about getting higher in Yahoo! and Google's search results pages.
We couldn't let this continue, and the easiest solution was simply to disallow robots from indexing search results pages. This had the added advantage of reducing the load the server was being caused by running all those searches that no one was looking at anyway. Also, no one wants to find a search results page linked from Google. If you are using a search engine to search for a particular topic, you want pages on that topic, not pages that redirect you to pages that redirect you to pages on that topic. From now on, all search results pages that I deal with will be disallowed to all bots. The bots themselves won't be doing any searches, anybody that links to them is likely to be up to no good and there's no point in search engines indexing them anyway.
To finish off, I thought I'd leave you with another quote from the same movie that the quote in the title is from: "It's a UNIX system! I know this!"
The Great Croatian Adventure (Part III - The Good Bits)
6pm, 21st October 2006 - TravelAlthough the comedy of errors we endured in Croatia makes for a good yarn, Croatia also provided us with a great time and the much needed sunshine and relaxation we sought after.
The culture was a real eye-opener for an Australian lad who had never been to any part of Europe before. Everything was just so very different. Coffee was a thick drink served in a small cup and stuck to the side of it. After tasting a few I realised that I had not had a good coffee before - ever. Every time we got off a bus or ferry there was a gaggle of people trying to convince us to stay in their apartments. Tourist shops and stalls seemed to all sell Croatian soccer uniforms.
The landscape blew me away. I imagined all the world was much like Australia in that it was built on dirt and had things like trees and shrubs and grasses growing in it. The dirt would be arranged into hills and valleys and plains and a small strip of sand seperating the land from the sea. How wrong I was ! Croatia is not made of dirt but rather it is made of rocks. Generally fist-sized grey rocks but they also have larger models. The rocks are arranged not into hills and valleys and plains but rather into mountains. That's all - mountains. The coast road winds it's way out around the spits and into the bays because the average angle of the first 500 metres in from to coast is 30 degrees. The next 500 metres after that gets even steeper and from what I saw of inland Croatia, the whole country is like that.
The Croatian people have, over the centuries, arranged a large number of their rocks into walls approximately a metre high and a foot thick that seem to run almost at random around the countryside. Sometimes they bordered what seemed to be a field and sometimes they looked like they had once been the walls of a house but mostly I couldn't figure out just what these walls were for. There are also some islands just off the coast that are made of dirt but have no plants at all. Just bare dirt. Some of them also have wind farms that look to be very well situated.
The economy seemd to revolve around fishing and tourism. Everybody we met was either a fisherman, a tourist or a tourist-based business operator.
All in all, Croatia was just amazingly different from everything I was already familiar with.
The Great Croatian Adventure (Part II - Getting back)
7am, 19th October 2006 - Humour, Travel English summers are not all they're cracked up to be... and they're not cracked up to much. Jane and I were looking paler than a pair of albino frogs in blenders. We needed a bit of sunshine, heat and if at all possible, a beach.
English summers are not all they're cracked up to be... and they're not cracked up to much. Jane and I were looking paler than a pair of albino frogs in blenders. We needed a bit of sunshine, heat and if at all possible, a beach.
{kind=link}
Italy has all of these things by all reports but don't they know it ! The costs of going to Italy were in line with it's reputation but our intrepid bargain hunter found out that Croatia is significantly cheaper and is remarkably similar in many respects to Italy. The websites all confirmed that it was full of sunshine and the random photos we found on flickr also made it seem like just the ticket.
I wrote about the first half of the journey earlier and promised the second half so here it is.
There was a mix-up of languages (and possibly some missing knowledge) on our last night in the hotel in Vis and the German/Croatian old guy manning the reception had some trouble figuring out what information we wanted and then, once he knew what we wanted, how to tell us what he knew. In the end he wrote down "830" on a piece of paper in response to our question about what time the ferry left in the morning.
We woke at 7:00 or so, saw the catamaran (not our ferry) leave at about 7:30, had a leisurely breakfast and wandered round to the ticket office to buy our tickets in advance. I was mildly concerned that the ferry was not in the bay as it had been last night when I went to sleep but there was plenty of time for it to arrive before it had to leave again at 8:30.
The ticket office was not open and didn't open until 10:30. We asked around and found out the reason for this was that the ferry left at 12:30... and 5:30am. We had missed it by several hours and the next one wasn't for several more. This put a bit of a spin on our plans of catching the bus from Split at 11:00am back to Rijeka in time for our 10:30pm flight... the timings just weren't right. 12:30 + 2 hours for the ferry + 8 hours on the bus wasn't going to get us to Rijeka before the plane left (actually, it might have... the plane was late but we didn't know that at the time.) so we started investigating alternative routes.
At first we thought of just trying to catch up to the ferry, after all it was only a couple of hours ahead of us. If we could charter a fast boat we could be in Split in time for the same bus we had planned on catching. Again, we asked around but it seems that you can't hurry a Croatian. Especially one who lives in a lazy fishing island of fewer than 1000 people. One guy said he could ask a friend on a neighbouring island to drive his speedboat over here and then to Split for a measly 400.
The Croatian currency, the Kuna, is worth about 10p. Our hotel was 600 Kunas per night so 400 seemed all right, certainly cheaper than missing the flight and having to stay another night. However, he mumbled something after the "400" that didn't sound very much like "Kunas". I asked him to repeat it and it sounded distinctly like he said "Euros" which aren't quite so cheap. In fact, Euros are worth more than Australian dollars so 400 of them wasn't going to be cheaper than staying another night... not by a long shot.
The decision was made to catch the next ferry at 12:30 because that was the only practical way off this island and hire a car to drive to Rijeka. We tried to book the car over the internet and locate a car hire place near where we would land in Split but it was not to be. Croatian car hire websites leave a lot to be desired in terms of functionality. We found ourselves in Split at 2:30pm, 6 hours later than we had intended with little more than a vague outline of a plan. A taxi driver told us that the nearest car-hire place was only 200 metres away, just past the McDonalds but it would take him about 15 minutes to drive there due to one way streets so we decided to walk. 300 metres later we see a sign stating that Maccas was only 400 metres... and when we finally found the place, it was closed until 5:30pm. Croatians also seem to like their afternoon naps.
Another taxi and another bright idea from Jane: "Take us to the airport ! They're sure to have car hire places there." They certainly did and we got in the line for the EuropCar booth which was one in a series of about 15 booths. After 20 minutes of listening to the lady in the booth pulling fee after charge after fee on the unsuspecting couple we went to the next booth along (EuropCar was the only one with a line...) and the lady in there was extremely helpful. She realised we were in a hurry and had everything finished in about 5 minutes and somebody from out the back bringing the car around so we wouldn't have to walk. We were in our car before the other couple had left the booth. Not only that, the car was about 2/3rds the price of the cheapest EuropCar available and that was before they had put on all those extra charges and fees.
I hadn't driven a car in 10 months and this one was a left-hand drive. I also didn't have my license with me so I was a little nervous as I drove around the very tightly packed car park to the outside world. The trip was reasonably uneventful in that "everything-is-backwards-and-on-the-wrong-side-and-very-very-fast" kind of way. The speed limit on Croatian highways is 130km/h however if you want to travel in the left hand lane you'd better be going a lot faster than that. I did 150km/h most of the way there in the middle lane and people were flying past me in the left lane. None of the pictures of Croatia's mountains really do them justice. They really are amazing. Also amazing are the tunnels that pass right through them. I was not uncommon for us to see a sign on the way into a tunnel stating that the tunnel was over 1.5km long.
We arrived in Rijeka at about 9:00pm and drove to the same coach stop that we had started at three days previously only to find that Rijeka was completely devoid of any signs pointing to the airport. All we had to guide us was a vague memory of what the trip from the airport had looked like three days ago. Amazingly, we made it to the airport with minutes to spare, parked the car in the first available spot and ran inside to check in. As we were checking our bags in we realised that we hadn't prepared them with the one-time tamper-proof tags and didn't have time to now but I joked that there wasn't really much that could go wrong; there was, after all, only one plane in the entire airport! After check-in we found the car-rental guy who sympathised with us about the lack of signage in Rijeka and returned the car keys.
The plane was delayed (the car-rental guy said that the Rijeka-Luton plane was always delayed. Usually by an hour or so.) so we sat around for a while and relaxed, now that we had caught up to our original plan of leaving the island on the first ferry.
Fast-forward to Luton airport and we are waiting to go through customs. There are three people manning the desks for EU passport holders and one guy checking the non-EU passport holders. They were being waved through with a cursory glance to make sure that the photo resembled the person holding it while we were being subject to a series of questions about why we were coming to England and how long we were staying. Then one girl, three or four ahead of us got stuck. We don't know what the cause was but she was still there when the entire other two lines (about 70% of the plane) were finished. We were waved through to the other two desks and got through the process just fine only to find at the baggage claim that Jane's bag had been moved off the conveyor belt into a little pile and my bag was nowhere to be seen. We waited and waited but eventually the conveyor belt was switched off and the remaining bags were put in the pile we found Jane's bag in. After some enquiries we headed to the desk where we could fill in a form about missing baggage. It seems that the woman behind that particular counter had misplaced her sense of humour as she wrote down "toothbrush" after asking me if there was anything valuable in the bag.
It's getting pretty late by now; the plane was delayed an hour, we were in the slow line for customs and my missing baggage had eaten up another hour or so. As we left the airport we spotted the poor girl who got stuck at the customs desk opening her bags and going through each item one by one, showing them to the same official who started the whole thing.
The shuttle bus to the train station wasn't due for another 45 minutes so we teamed up with a couple of people who had arrived on the next flight in and caught a taxi to the train station. The train was also going to be 45 minutes but after a failed attempt at sharing a taxi all the way home we ended up all catching the train together. One was a German who lived in England and had just come back from Berlin where he was a journalist covering a sporting event there. One was born in Berlin and was visiting friends and family and the last was a Londoner through and through but was a cabaret dancer who had been personally requested for a show in Berlin.
We got home around 3:30am and discovered that I had locked every lock on our door and Jane didn't have every key on her key chain and my keys were in my bag... in Croatia. After trying to break in a few times we gave up and trundled down to Michaela's place about 800 metres away and rang her mobile until she woke up. It is now around 4:30. We curl up on Michaela's couches and set our alarms in time to go to work. Jane is fine; she still has the clothes she was wearing on Friday when we left for Croatia so she just climbs back into them and sets off for work. I need to ring my work to say that I'll be late and pay a visit to our landlady to get the spare set of keys and get some more appropriate clothes. I couldn't ring work until 9:00 so it was decided that everyone else would leave and I could pull the door shut behind me when I left.
Unfortunately the landlord of the flat downstairs was showing a prospective tenant around the flat and deadlocked the door on their way out, trapping me inside Michaela's house. I spent some time contemplating the various ways of jumping out windows before ringing work and telling them that I wasn't going to make it in today. I then rang the real estate agent by sticking my head out of the window and dialing the number on the "to let" sign. Things went comparatively smoothly after that. My bags (apparently they were left on the tarmac... go figure !) were returned while I was at work the next day so they left them with the next door neighbours. (Who by some random chance just happened to be trustworthy enough not to rifle through my bags and take everything of value before denying all knowledge of ever receiving my bags.)
That wraps up the Croatian adventure. There were some good parts. In fact, there were plenty of good parts and with the knowledge I gained from this trip I think I could make another trip to Croatia much more enjoyable and less stressful. I'll write some more about the good bits at another time but for now you will have to be content with simply looking at some of the photos. Jane has created a flickr account and is uploading the best of our photos to it. I'm thinking of doing the same so I'll let you all know if that happens.
Avoid my language problems, get your Lonely Planet Language Guides
before you go !
Oooooh, shiny !
7am, 6th October 2006 - Geek, News, Web, Developer, SysadminLast night I put my mind to making prettier URLs and now I have them. "What's a pretty URL?" I hear you ask. (Actually, "What's a URL?") A URL is the line of text you have to type in to your browser near the top to bring up this web page. It probably looks like "http://ladadadada.dyndns.org/blog/2006/10/06" but in the not so distant past, it looked like "http://ladadadada.dyndns.org/blog/?date=1159085547". Why is the new version prettier ? Well, 2006/10/06 is much easier to remember than 1159085547. It's the same number of characters but the new version means something. They're also much easier for people to manipulate; say you wanted my blog entry from yesterday, just change the 2006/10/03 to 2006/10/02. With the old method, you'd have to subtract 86400 from 1159085547 and hope that I posted the blog entry at the exact same second of the same minute of the same hour one day ago.
I think I'll add a month thingy so that you can just type 2006/09 to get all of the posts from September 2006. Also, search engines such as Google prefer URLs that don't have "?" in them.
For all you TBL fans out there, don't worry, my old URIs still work. I even stuck in some rewrite rules so that old sections that no longer exist will still take you to the nearest equivalent or provide you with a custom error message explaining why you can't find what Google said was on my site.
So, enough geekery! The next installment of this blog will be the second half of the Great Croatian Adventure in which Jane and I attempt to leave Croatia and return to our homes.
The Great Croatian adventure (Part I - Getting there)
8am, 24th September 2006 - Humour, TravelIt's been two weeks now since the Croatian adventure so it's time to preserve for posterity the happenings of that fateful weekend.
It all started with a dismal English summer that just didn't meet our Australian expectations. It barely got above thirty degrees, there are no beaches in London, there was not a barbeque in sight nor smelling range and we don't even have a back yard. Apparently this was quite good for an English summer, in fact, some of my workmates were even complaining about the heat !
The decision was made to have a quick holiday somewhere a little further South before summer was finished. Various proposals were floated... and sank. The Cornwall trip got cancelled due some silly git evicting our Aussie friend from her house the week before we were due to go, resulting in her staying home and searching for a new house instead, so Jane and I set our sights on Italy.
After a little investigation, we found that flights to Croatia were far cheaper than Italy and their cultures and climates are surprisingly similar. You only need to look at the way they play soccer for some evidence of that! Jane purchased the "Rough Guide" to Croatia and we planned where we would go and what we would do.
We left straight from work via train to Luton, plane to Rijeka and bus to the centre of town where a coach was supposed to take us overnight to Split just in time for a ferry to Vis. The folly of not having a "Plan B" is, unfortunately, well known to me. The plane from Luton was delayed (They messed up the allowable flight times of some of the crew on a plane from Berlin so our plane and it's crew went there instead and we had to wait for another one. We found out later from the car-hire guy in Rijeka airport that the Luton flight is always late, usually by an hour or so.) with no explanation of what was going on. The boarding time up on the screens that were dotted around the airport came and went and the message continued to say "Wait in foyer". The message also urged us to buy more in the available shops because although we were only allowed one piece of hand luggage on board, shopping bags were not included in that tally.
The flight was uneventful but the descent was quite a ride. The turbulence that I guess was caused by the mountainous terrain that forms the coast of Croatia was severe enough that we all felt like we were on a roller-coaster. Stomachs dropping, small amounts of free-fall, being squashed down into your seat and the most concerning/exciting of all: an occasional, unnanounced side wind that would turn the aircaft thirty or forty degrees away from the direction of travel and into the wind. I've never been in a plane that was slipping sideways through the air before.
Arriving in Rijeka via the bus from the airport (Twenty Kunas! You want twenty Kunas! What's that in Pounds? Oh. Never mind, here you go.) at 1:30am we tried to make sense of the coach timetable which, once decyphered, proclaimed that the last coach left at 12:00am and the next coach would not be until 7:00am. A taxi ride to the train station (300 metres. It was closed.) and to the nearest decent hotel (400 metres back the way we came.) and we lay our weary heads down to rest.
Breakfast was put on by the hotel at around 6:30am and we checked out by around 7:00am. Of course, we missed the first bus but we thought the next one was at 8:00am. It was actually at 9:00am so we had some time to kill.  Jane went wandering with the camera while I befriended some of the people looking as tired as I felt who were also waiting at the coach stop. It seems they were on the same plane as us but they had decided to catch a taxi one city closer to their destination before finding somewhere to sleep but actually caught the taxi the wrong way and walked back. The four hours we spent sleeping they spent walking.
Jane went wandering with the camera while I befriended some of the people looking as tired as I felt who were also waiting at the coach stop. It seems they were on the same plane as us but they had decided to catch a taxi one city closer to their destination before finding somewhere to sleep but actually caught the taxi the wrong way and walked back. The four hours we spent sleeping they spent walking.
The bus trip took eight hours which put us in Split around 5:00pm which was plenty of time to catch the ferry at 8:00pm for Vis. Vis is a small, relaxed island about 40km off the coast of Croatia. Nothing is done in a hurry on Vis unless you want to pay someone a lot of money to speed things up. As far as our relaxing, sun-drenched holiday was concerned, it was perfect.
Coming home was another matter.
Avoid my language problems, get your Lonely Planet Language Guides
before you go !
AAAarrrgh ! Human pop-ups !
7am, 8th September 2006 - RantFor the last week or so I have had to contend with the real-life equivelant of pop-up windows. It's like Agent Smith finding a way aboard the Nebakanezer when we all thought he was just an AI construct.
There have been two new free newspapers released in the last week and both of them are trying for the same market (free, evening news). Their methods seem to be to attempt to promote the newspaper by having lots of people handing out the newspapers from 5:00pm onwards around the major tube stations.
Near my tube station, one enterprising lad realised that nearly half of the commuters came around the same corner on their way to the station so he moved his operation to just before that corner so that he would have first pick and therefore hand out more newspapers. (I guess that when their support van runs out of papers, they go home but this strategy would look good for him because he would be going back for a top-up more often than the others.) The others soon cottoned on and now they have people stationed on every corner within 100 metres of the station; it's impossible to avoid them.
The worst part about it all is that they don't care about what they are doing. They don't notice that you have already walked past three people trying to offer you a paper and you have turned each one of them down. The don't even notice when you accept one and are walking along with a paper in hand... they will still offer you another copy of the same newspaper. In the worst case, nearest the station, two different people will sometimes offer you two copies of the same paper within a metre of each other.
Give it a rest already. I've read the paper and it was terrible. Full of useless gossip about Big-Brother and the WAGs and not a single thought-provoking article at all. They even seem to be quite proud of the sections where random people write in and offer their opinion on some random topic. Let me give you a hint: Regular columnists are good because you get to know which ones you like and can filter based on the name of the columnist. With these random people, you have to read a significant portion of the article before realising that the writer is an idiot and not worth listening to but you have to keep reading every day because you don't know if today might be the day where someone intelligent writes in.
Maybe it will get better. Maybe this is actually what people want and I'm just too fussy.
Maybe not.
In either case... please, please, plaese stop trying to force your paper down my throat.
Submit, Reset.
9pm, 1st September 2006 - Geek, Rant, Web, DeveloperWhat is the Reset button for ? Honestly, has anyone, anywhere, ever actually USED the Reset button ?
Here's the scenario:
You are filling in a form online. Let's say it's your annual tax return and it's quite long and complicated (as tax forms are...) You reach the end and go to click the "Submit" button but you pause. Have I filled in everything correctly ? This is important... I'd better check...
Oh. My. God.
I've filled everything in wrong. My income, my dependants, my job title, the date and even my own name. Everything.
I wonder if there's an easy way to clear every field and start over again ?
Convoluted ? Sure, but it had to be to find a use for that button. And of course, you could always reload the page. In most cases, you only want to adjust one or maybe two fields on a page because you filled them out incorrectly and if you don't want to submit the form anymore, just navigate away from the page. It's not a real, paper form where you need to rub out all your answers before throwing it in the bin. Yet for some reason, web forms seem to always have a button. It's like developers were taught to put a submit button, then a reset button then close the form tag and they have never questioned whether they really want to because "That's the way it's done."
While I'm on the topic... Submit buttons with the default value of "Submit" bug me. Apple got it right with their Human Interface Guidelines - a control should give some idea of what it is going to do when you click on it. Give me a hint; is this button going to solve a puzzle for me ? Call it "Solve". Will it book a hotel ? Call it "Book hotel". Will it search a database and display the results ? Call it "Search".
It doesn't have to inventive; it has to be informative. Put your brain to it; can you think of a more descriptive word than "Submit" ? I think you can.
Internet Explorer exceeds all expectations.
7am, 25th August 2006 - Geek, Microsoft, SecurityLet me be the first to congratulate the IE team on their remarkable achievement in releasing their most obvious security vulnerability yet.
According to the Secunia Advisory, the vulnerability happens during the parsing of a URL while using HTTP 1.1 and compression.
Honestly, a URL. Who would have thought that a URL could be controlled by malicious people and therefore would be a danger that needed bounds checking ? Oh yes, did I forget to mention that the exploit was a buffer overflow that results in arbitrary code being executed on the target machine and, if the code is right, system access ?
Now I know what they say about people who live in glass houses, and that my website isn't all that secure and that security flaws could be found that would lead to XSS attacks or possibly SQL injection (although I have been fairly careful about the SQL injection side of things) but in my defense, I don't get paid for this and there's only one of me. There are hundreds of guys who make IE and they get paid well for it. It should be better, and it isn't. Of course, you can always get Firefox. If you use the advert underneath the navigation I may even get paid for you choosing a more secure browser !
Some quick links to the relevant Secunia pages containing the security records of other browsers...
Firefox
Internet Explorer
Safari
Opera
Sudoku solving version alpha
9pm, 18th August 2006 - Geek, News, Web The Sudoku page is now good enough at solving Sudoku games that it can do anything labeled "easy" or "medium" and can do some of the ones labeled "hard". I have the code mapped out in my head that will solve the rest of the "hard" ones but I'm concentrating on adding a few features before I finish that bit.
The Sudoku page is now good enough at solving Sudoku games that it can do anything labeled "easy" or "medium" and can do some of the ones labeled "hard". I have the code mapped out in my head that will solve the rest of the "hard" ones but I'm concentrating on adding a few features before I finish that bit.
Which brings me to the features. If you solve a square, the square is highlighted and an elementary explanation of why we filled in that square is printed at the bottom. If you solve ten squares at once, they are all highlighted but no explanation is printed. If you ask for a hint, the square is highlighted but the number is not filled in and the explanation is still printed at the bottom.
The code is also mapped out in my head for more detailed explanations and highlighting (in a different colour) of the parts of the board that lead to the elementary explanation.
The next feature after that will be AJAX. What's AJAX ? It's just a technology that allows the Sudoku page to work without having to reload the entire page every time you click one of the buttons. When you click them your computer simply asks the server for the bits of the page that need to be changed and it changes only those bits. It makes the page seem more responsive because less data is being transmitted to the server and back.
I don't know whether to be proud or ashamed.
9pm, 6th August 2006 - Geek, News, Web I just got beaten to the finish in a game of Sudoku. Not that unusual in itself; Jane is much better at Sudoku than I am but it wasn't Jane who beat me. It was a program that I wrote.
I just got beaten to the finish in a game of Sudoku. Not that unusual in itself; Jane is much better at Sudoku than I am but it wasn't Jane who beat me. It was a program that I wrote.
The Sudoku page is up an available and it can finish some Sodoku games. It can finish them faster than I can. It can't finish all of the games because I only have two of the five parts of the algorithm completed but those two are enough to finish at least one board (board number 4).
I'll be working on it some more in the coming weeks and hopefully soon it will be able to solve even the hard Sudoku games... maybe even faster than Jane ! After that, it will be able to create new Sudoku games and start doing fancy things like suggesting moves, providing hints at moves and highlighting rows, columns, blocks and mistakes you may have made.
Time to move on
4pm, 5th August 2006 - NewsAs of yesterday, I am no longer employed. I terminated my contract at MoneySavingExpert a couple of weeks early so that I could start a new, permanent position at IPC Media.
I haven't signed my contract for IPC Media yet so at the time of writing this I am unemployed.
Another part comes to life.
7pm, 30th July 2006 - Geek, News, WebThe rss feed is working again. Blog entries can now be subscribed to. Once I finish writing an article or two I'll set up the article rss feed as well.
Strangely enough, the sudoku page seems to be one of the most popular pages on the website, even though all it does at the moment is fill a sudoku board with random numbers. I probably should do some work on it then shouldn't I ?
How may I help you today ?
8am, 10th July 2006 - RantI have finally experienced the full extent of just how poor customer service is here in the UK.
I thought it was bad when my bank had a problem with the payments on my credit card and rather than sending me a letter or calling me or even emailing me, they chose to communicate by cutting my credit card off. I thought that was bad, but they were quite happy to talk when I rang them up and asked to be allowed to use my credit card again. They even refunded the £20 fee they had charged me without being asked to.
Bulldog Broadband, on the other hand, wrote a letter dated 22nd June which stated that my broadband services would be restricted seven days from the date of the letter. Then they forgot to send it. Eventually, they found the letter again and sent it off, but by this time we already had no internet and no phone because we have a bundled service that includes our phone as well.
The good news is that their customer support phone number is a free call; I have no problems talking to them all day because I'm not constantly thinking about how much it's costing me. The bad news is that their training consists of two sentences: "If a customer calls you, push this button to fix their problem. If they don't ask you to push that button, tell them to ring the correct department." The people on the end of the phone discovered that they could shunt you around for days on end without even really trying. They can't even transfer you to the correct department, you have to ring back again and go through the talking computer menu options which, incidentally, take one minute and thirty two seconds before you can even choose the first option... every time.
I rang back so many times that in the end, I started hitting the same guys again. How many of you have actually called a call centre so many times that the people on the end of the phone know your voice ?
As I write this, 5 days after I first rang them, having called them and spoken for an average of 30 minutes every day, I still have no access to the internet.
The excuses they gave also varied a bit; I was told that they had recently changed the billing system and it may have lost my details, the the billing system was down (twice, by two different people on two different days. I called straight back and a different person told me that the billing system was fine.), that they didn't have the ability to transfer phone calls to a different department, that I was being transferred to a different department, that the person concerned didn't have a supervisor, that they "don't have supervisors here", that the supervisors don't start work until 10:00am (I was calling at 9:00am), that the supervisor wouldn't take my call, that the supervisor would only tell me the same thing as the person concerned was and finally, that I had been placed in a queue for the supervisor to call back... which never happened.
All in all, I think I should have believed the girl who told me the billing system was down, cancelled my account and signed up with another provider. I'd be £168.39 richer, I'd probably have acess to the internet by now and I woudn't have wasted two and a half hours on the phone to people who weren't interested at all in helping me.
Clawing my way back on to the web
6am, 25th June 2006 - Geek, News, WebThe website is finally back up. Parts will become available as I get more of it back in place but for now, the middle name guesser is ready to go.